Certification exam development, as well as other credentialing like licensure or certificates, is incredibly important. Such exams serve as gatekeepers into many professions, often after people have invested a ton of money and years of their life in preparation. Therefore, it is critical that the tests be developed well, and have the necessary supporting documentation to show that they are defensible. So what exactly goes into developing a quality exam, sound psychometrics, and establishing the validity documentation, perhaps enough to achieve NCCA accreditation for your certification?
Well, there is a well-defined and recognized process for certification exam development, though it is rarely the exact same for every organization. In general, the accreditation guidelines say you need to address these things, but leave the specific approach up to you. For example, you have to do a cutscore study, but you are allow to choose Bookmark vs Angoff vs other method.
Job Analysis / Practice Analysis
A job analysis study provides the vehicle for defining the important job knowledge, skills, and abilities (KSA) that will later be translated into content on a certification exam. During a job analysis, important job KSAs are obtained by directly analyzing job performance of highly competent job incumbents or surveying subject-matter experts regarding important aspects of successful job performance. The job analysis generally serves as a fundamental source of evidence supporting the validity of scores for certification exams.
Test Specifications and Blueprints
The results of the job analysis study are quantitatively converted into a blueprint for the exam. Basically, it comes down to this: if the experts say that a certain topic or skill is done quite often or is very critical, then it deserves more weight on the exam, right? There are different ways to do this. My favorite article on the topic is Raymond & Neustel, 2006. Here’s a free tool to help.

Item Development
After important job KSAs are established, subject-matter experts write test items to assess them. The end result is the development of an item bank from which exam forms can be constructed. The quality of the item bank also supports test validity. A key operational step is the development of an Item Writing Guide and holding an item writing workshop for the SMEs.
Pilot Testing
There should be evidence that each item in the bank actually measures the content that it is supposed to measure; in order to assess this, data must be gathered from samples of test-takers. After items are written, they are generally pilot tested by administering them to a sample of examinees in a low-stakes context—one in which examinees’ responses to the test items do not factor into any decisions regarding competency. After pilot test data is obtained, a psychometric analysis of the test and test items can be performed. This analysis will yield statistics that indicate the degree to which the items measure the intended test content. Items that appear to be weak indicators of the test content generally are removed from the item bank or flagged for item review so they can be reviewed by subject matter experts for correctness and clarity.
Note that this is not always possible, and is one of the ways that different organizations diverge in how they approach exam development.
Standard Setting
Standard setting also is a critical source of evidence supporting the validity of professional credentialing exam (i.e. pass/fail) decisions made based on test scores. Standard setting is a process by which a passing score (or cutscore) is established; this is the point on the score scale that differentiates between examinees that are and are not deemed competent to perform the job. In order to be valid, the cutscore cannot be arbitrarily defined. Two examples of arbitrary methods are the quota (setting the cut score to produce a certain percentage of passing scores) and the flat cutscore (such as 70% on all tests). Both of these approaches ignore the content and difficulty of the test. Avoid these!
Instead, the cutscore must be based on one of several well-researched criterion-referenced methods from the psychometric literature. There are two types of criterion-referenced standard-setting procedures (Cizek, 2006): examinee-centered and test-centered.
The Contrasting Groups method is one example of a defensible examinee-centered standard-setting approach. This method compares the scores of candidates previously defined as Pass or Fail. Obviously, this has the drawback that a separate method already exists for classification. Moreover, examinee-centered approaches such as this require data from examinees, but many testing programs wish to set the cutscore before publishing the test and delivering it to any examinees. Therefore, test-centered methods are more commonly used in credentialing.
The most frequently used test-centered method is the Modified Angoff Method (Angoff, 1971) which requires a committee of subject matter experts (SMEs). Another commonly used approach is the Bookmark Method.
Equating
If the test has more than one form – which is required by NCCA Standards and other guidelines – they must be statistically equated. If you use classical test theory, there are methods like Tucker or Levine. If you use item response theory, you can either bake the equating into the item calibration process with software like Xcalibre, or use conversion methods like Stocking & Lord.
What does this process do? Well, if this year’s certification exam had an average of 3 points higher than last years, how do you know if this year’s version was 3 points easier, or this year’s cohort was 3 points smarter, or a mixture of both? Learn more here.
Psychometric Analysis & Reporting
This part is an absolutely critical step in the exam development cycle for professional credentialing. You need to statistically analyze the results to flag any items that are not performing well, so you can replace or modify them. This looks at statistics like item p-value (difficulty), item point biserial (discrimination), option/distractor analysis, and differential item functioning. You should also look at overall test reliability/precision and other psychometric indices. If you are accredited, you need to perform year-end reports and submit them to the governing body. Learn more about item and test analysis.
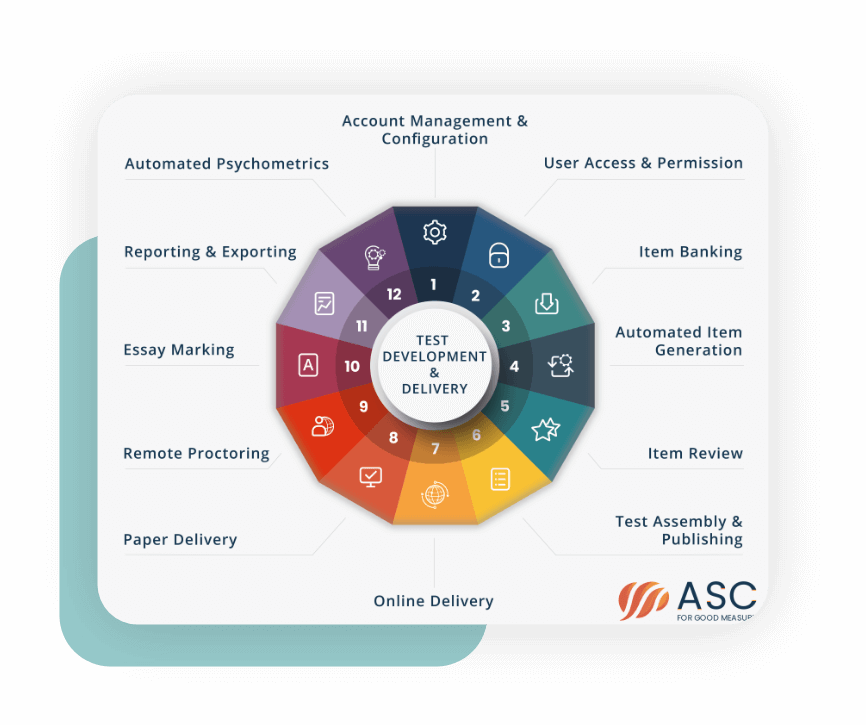
Exam Development: It’s a Vicious Cycle
Now, consider the big picture: in many cases, an exam is not a one-and-done thing. It is re-used, perhaps continually. Often there are new versions released, perhaps based on updated blueprints or simply to swap out questions so that they don’t get overexposed. That’s why this is better conceptualized as an exam development cycle, like the circle shown above. Often some steps like Job Analysis are only done once every 5 years, while the rotation of item development, piloting, equating, and psychometric reporting might happen with each exam window (perhaps you do exams in December and May each year).
ASC has extensive expertise in managing this cycle for professional credentialing exams, as well as many other types of assessments. Get in touch with us to talk to one of our psychometricians.





 Usually, there is a test that you must pass, but the sponsor can differ with certification vs licensure. The development and delivery of such tests is extremely similar, leading to the confusion. They often will both utilize
Usually, there is a test that you must pass, but the sponsor can differ with certification vs licensure. The development and delivery of such tests is extremely similar, leading to the confusion. They often will both utilize