A psychometrician is someone who studies the process of assessment, namely how to develop and validate exams, regardless of the type of assessment (certification, employment, university admissions, K-12, etc.). They are familiar with the scientific literature devoted to the development of fair, high-quality assessments, and they use this knowledge to improve assessments. They implement aspects of engineering, data science, and machine learning to ensure that tests provide accurate information about people, so we can make decisions.
What is a Psychometrician?
A psychometrician is like a lead engineer, applying best practices to produce a complex product that is reliable and serves the purpose of the test, such as predicting job performance. This involves planning, management of a team of specialists, ensuring quality control, and other leadership. However, psychometricians are often the type that like to get their hands dirty by writing code and analyzing data themselves.
In some parts of the world, the term psychometrician refers to someone who administers tests, typically in a counseling setting, and does not actually know anything about the development or validation of tests. That usage is incorrect; such a person is a psychometrist, as you can see at the website for the here. Even major sites like ZipRecruiter don’t do the basic fact-checking to get this straight.

What does a psychometrician do?
There are many steps that go into developing a high quality, defensible assessment. These differ by the purpose of the test. When working on professional certifications or employment tests, a job analysis is typically necessary and is frequently done by a psychometrician. Yet job analysis totally irrelevant for K-12 formative assessments; the test is based on a curriculum, so a psychometrician’s time is spent elsewhere.
Some topics include:
This is a highly quantitative profession. Psychometricians spend most of their time working with datasets, using specially designed software or writing code in languages like R and Python.
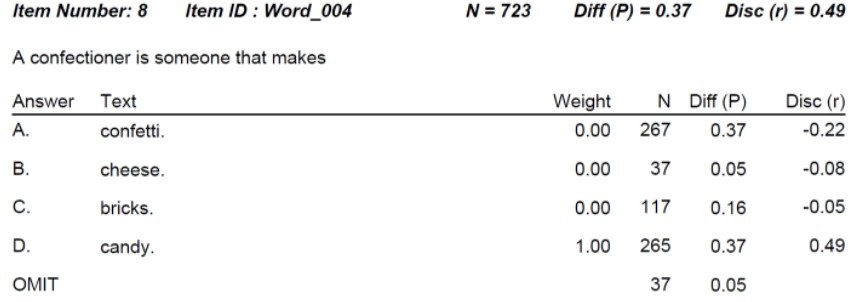
A simple example of item analysis is shown below. This is an English vocabulary question. This question is extremely difficult; only 37% of students get it correct even though there is a 25% chance just by guessing. The item would probably be flagged for review. However, the point-biserial discrimination is extremely high, telling us that the item is actually very strong and defensible. Lots of students choose “confetti” but it is overwhelmingly the lower students, which is exactly what we want to have happen!
Where does a psychometrician work?
They work any place that develops high-quality tests. Some examples:
- Large educational assessment organizations like ACT
- Governmental organizations like Singapore Examinations and Assessment Board
- Professional certification and licensure boards like the International Federation of Boards of Biosafety
- Employment testing companies like Biddle Consulting Group
- Medical research like PROMIS
- Universities like the University of Minnesota – mostly in purely academic roles
- Language assessment groups like Berlitz
- Testing services companies like ASC; such companies provide psychometric services and software to organizations that cannot afford to hire their own fulltime psychometrician. This is often the case with certification and licensure boards.
What skills do I need?
There are two types of psychometrician: client-facing and data-facing. Though many psychometricians have skills in both domains.
Client-facing psychometricians excel in what one of my former employers called Client Engagements; parts of the process where you work directly with subject matter experts and stakeholders. Examples of this are job analysis studies, test design workshops, item writing workshops, and standard setting. All of these involve the use of an expert panel to discuss certain aspects. The skills you need here are soft skills; how to keep the SMEs engaged, meeting facilitation and management, explaining psychometric concepts to a lay person, and – yes – small talk during breaks!
Data-facing psychometricians focus on the numbers. Examples of this include equating, item response theory analysis, classical test theory reports, and adaptive testing algorithms. My previous employer called this the Client Reporting Team. The skills you need here are quite different, and center around data analysis and writing code.
How do I get a job as a psychometrician?
First, you need a graduate degree. In this field, a Master’s degree is considered entry-level, and a PhD is considered a standard level of education. It can often be in a related area like I/O psychology. Given that level of education, and the requirement for advanced data science skills, this career is extremely well-paid.
Wondering what kind of opportunities are out there? Check out the NCME Job Board and Horizon Search, a headhunter for assessment professionals.
Are all they created equal?
Absolutely not! Like any other profession, there are levels of expertise and skill. I liken it to top-level athletes: there are huge differences between what constitutes a good football/basketball/whatever player in high school, college, and the professional level. And the top levels are quite elite; many people who study psychometrics will never achieve them.
Personally, I group psychometricians into three levels:
Level 1: Practitioners at this level are perfectly comfortable with basic concepts and the use of classical test theory, evaluating items and distractors with P and Rpbis. They also do client-facing work like Angoff studies; many Level 2 and Level 3 psychometricians do not enjoy this work.
Level 2: Practitioners at this level are familiar with advanced topics like item response theory, differential item functioning, and adaptive testing. They routinely perform complex analyses with software such as Xcalibre.
Level 3: Practitioners at this level contribute to the field of psychometrics. They invent new statistics/algorithms, develop new software, publish books, start successful companies, or otherwise impact the testing industry and science of psychometrics in some way.
Note that practitioners can certainly be extreme experts in other areas: someone can be an internationally recognized expert in Certification Accreditation or Pre-Employment Selection but only be a Level 1 psychometrician because that’s all that’s relevant for them. They are a Level 3 in their home field.
Do these levels matter? To some extent, they are just my musings. But if you are hiring a psychometrician, either as a consultant or an employee, this differentiation is worth considering!
 Response Similarity Index") .
.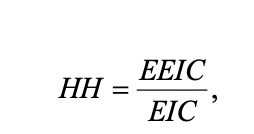


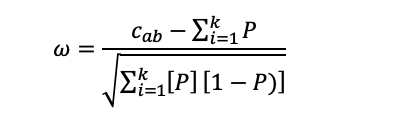
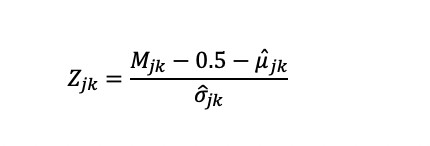



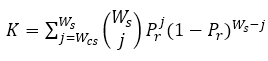

 .
.