
What is Psychometrics?
Psychometrics is the science of educational and psychological assessment. It scientifically studies how tests are developed, delivered, and scored, regardless of the test topic. Psychometrics tackles fundamental questions around assessment, such as how to determine if a test is reliable or if a question is of good quality, as well as much more complex questions like how to ensure that a score today means the same thing as it did 10 years ago.
Why do we need psychometrics?
This purpose of tests is providing useful information about people, such as whether to hire them, certify them in a profession, or determine what to teach them next in school. Better tests mean better decisions. Why? The scientific evidence is overwhelming that tests provide better information for decision makers than many other types of information, such as interviews, resumes, or educational attainment. Thus, tests serve an extremely useful role in our society.
The goal of psychometrics is to provide validity: evidence to support that interpretations of scores from the test are what we intended. If a certification test is supposed to mean that someone passing it meets the minimum standard to work in a certain job, we need a lot of evidence about that, especially since the test is so high stakes in that case.
What is psychometrics? An introduction / definition.
Psychometrics is the study of assessment itself, regardless of what type of test is under consideration. In fact, many psychometricians don’t even work on a particular test, they just work on psychometrics itself, such as new methods of data analysis. Most professionals don’t care about what the test is measuring, and will often switch to new jobs at completely unrelated topics, such as moving from a K-12 testing company to psychological measurement to an Accountant certification exam. We often refer to whatever we are measuring simply as “theta” – a term from item response theory.
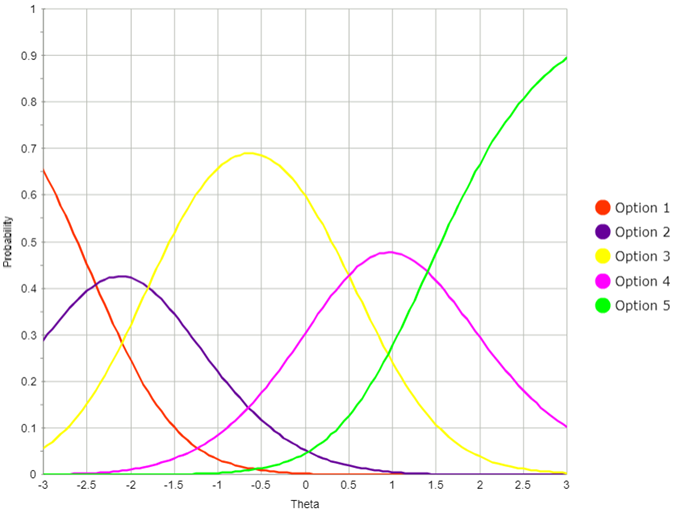
Psychometrics is a branch of data science. In fact, it’s been around a long time before that term was even a buzzword. Don’t believe me? Check out this Coursera course on Data Science, and the first example they give as one of the foundational historical projects in data science is… psychometrics! (early research on factor analysis of intelligence)
Even though assessment is everywhere and Psychometrics is an essential aspect of assessment, to most people it remains a black box, and professionals are referred to as “psychomagicians” in jest. However, a basic understanding is important for anyone working in the testing industry, especially those developing or selling tests. It’s also important for many areas that use assessments, like human resources and education.
Psychometrics is NOT limited to very narrow types of assessment. Some people use the term interchangeably with concepts like IQ testing, personality assessment, or pre-employment testing. These are each but tiny parts of the field! Also, it is not the administration of a test.
What questions does the field of Psychometrics address?
Building and maintaining a high-quality test is not easy. A lot of big issues can arise. Much of the field revolves around solving major questions about tests: what should they cover, what is a good question, how do we set a good cutscore, how do we make sure that the test predicts job performance or student success, etc. Many of these questions align with the test development cycle – more on that later.
How do we define what should be covered by the test? (Test Design)
Before writing any items, you need to define very specifically what will be on the test. If the test is in credentialing or pre-employment, psychometricians typically run a job analysis study to form a quantitative, scientific basis for the test blueprints. A job analysis is necessary for a certification program to get accredited. In Education, the test coverage is often defined by the curriculum.
How do we ensure the questions are good quality? (Item Writing)
There is a corpus of scientific literature on how to develop test items that accurately measure whatever you are trying to measure. A great overview is the book by Haladyna. This is not just limited to multiple-choice items, although that approach remains popular. Psychometricians leverage their knowledge of best practices to guide the item authoring and review process in a way that the result is highly defensible test content. Professional item banking software provides the most efficient way to develop high-quality content and publish multiple test forms, as well as store important historical information like item statistics.
How do we set a defensible cutscore? (Standard Setting)
Test scores are often used to classify candidates into groups, such as pass/fail (Certification/Licensure), hire/non-hire (Pre-Employment), and below-basic/basic/proficient/advanced (Education). Psychometricians lead studies to determine the cutscores, using methodologies such as Angoff, Beuk, Contrasting-Groups, and Borderline.
How do we analyze results to improve the exam? (Psychometric Analysis)
Psychometricians are essential for this step, as the statistical analyses can be quite complex. Smaller testing organizations typically utilize classical test theory, which is based on simple mathematics like proportions and correlations. Large, high-profile organizations typically use item response theory (IRT), which is based on a type of nonlinear regression analysis. Psychometricians evaluate overall reliability of the test, difficulty and discrimination of each item, distractor analysis, possible bias, multidimensionality, linking multiple test forms/years, and much more. Software such as Iteman and Xcalibre is also available for organizations with enough expertise to run statistical analyses internally. Scroll down below for examples.
How do we compare scores across groups or years? (Equating)
This is referred to as linking and equating. There are some psychometricians that devote their entire career to this topic. If you are working on a certification exam, for example, you want to make sure that the passing standard is the same this year as last year. If you passed 76% last year and this year you passed 25%, not only will the candidates be angry, but there will be much less confidence in the meaning of the credential.
How do we know the test is measuring what it should? (Validity)
Validity is the evidence provided to support score interpretations. For example, we might interpret scores on a test to reflect knowledge of English, and we need to provide documentation and research supporting this. There are several ways to provide this evidence. A straightforward approach is to establish content-related evidence, which includes the test definition, blueprints, and item authoring/review. In some situations, criterion-related evidence is important, which directly correlates test scores to another variable of interest. Delivering tests in a secure manner is also essential for validity.
Where is Psychometrics Used?
Certification/Licensure/Credentialing
In certification testing, psychometricians develop the test via a documented chain of evidence following a sequence of research outlined by accreditation bodies, typically: job analysis, test blueprints, item writing and review, cutscore study, and statistical analysis. Web-based item banking software like FastTest is typically useful because the exam committee often consists of experts located across the country or even throughout the world; they can then easily log in from anywhere and collaborate.
Pre-Employment
In pre-employment testing, validity evidence relies primarily on establishing appropriate content (a test on PHP programming for a PHP programming job) and the correlation of test scores with an important criterion like job performance ratings (shows that the test predicts good job performance). Adaptive tests are becoming much more common in pre-employment testing because they provide several benefits, the most important of which is cutting test time by 50% – a big deal for large corporations that test a million applicants each year. Adaptive testing is based on item response theory, and requires a specialized psychometrician as well as specially designed software like FastTest.
K-12 Education
Most assessments in education fall into one of two categories: lower-stakes formative assessment in classrooms, and higher-stakes summative assessments like year-end exams. Psychometrics is essential for establishing the reliability and validity of higher-stakes exams, and on equating the scores across different years. They are also important for formative assessments, which are moving towards adaptive formats because of the 50% reduction in test time, meaning that student spend less time testing and more time learning.
Universities
Universities typically do not give much thought to psychometrics even though a significant amount of testing occurs in higher education, especially with the move to online learning and MOOCs. Given that many of the exams are high stakes (consider a certificate exam after completing a year-long graduate program!), psychometricians should be used in the establishment of legally defensible cutscores and in statistical analysis to ensure reliable tests, and professionally designed assessment systems used for developing and delivering tests, especially with enhanced security.
Medicine/Psychology
Have you ever taken a survey at your doctor’s office, or before/after a surgery? Perhaps a depression or anxiety inventory at a psychotherapist? Psychometricians have worked on these.
The Test Development Cycle
Psychometrics is the core of the test development cycle, which is the process of developing a strong exam. It is sometimes called similar names like assessment lifecycle.
You will recognize some of the terms from the introduction earlier. What we are trying to demonstrate here is that those questions are not standalone topics, or something you do once and simply file a report. An exam is usually a living thing. Organizations will often be republishing a new version every year or 6 months, which means that much of the cycle is repeated on that timeline. Not all of it is; for example, many orgs only do a job analysis and standard setting every 5 years.
Consider a certification exam in healthcare. The profession does not change quickly because things like anatomy never change and medical procedures rarely change (e.g., how to measure blood pressure). So, every 5 years it does a job analysis of its certificants to see what they are doing and what is important. This is then converted to test blueprints. Items are re-mapped if needed, but most likely do not need it because there are probably only minor changes to the blueprints. Then a new cutscore is set with the modified-Angoff method, and the test is delivered this year. It is delivered again next year, but equated to this year rather than starting again. However, the item statistics are still analyzed, which leads to a new cycle of revising items and publishing a new form for next year.
Example of Psychometrics in Action
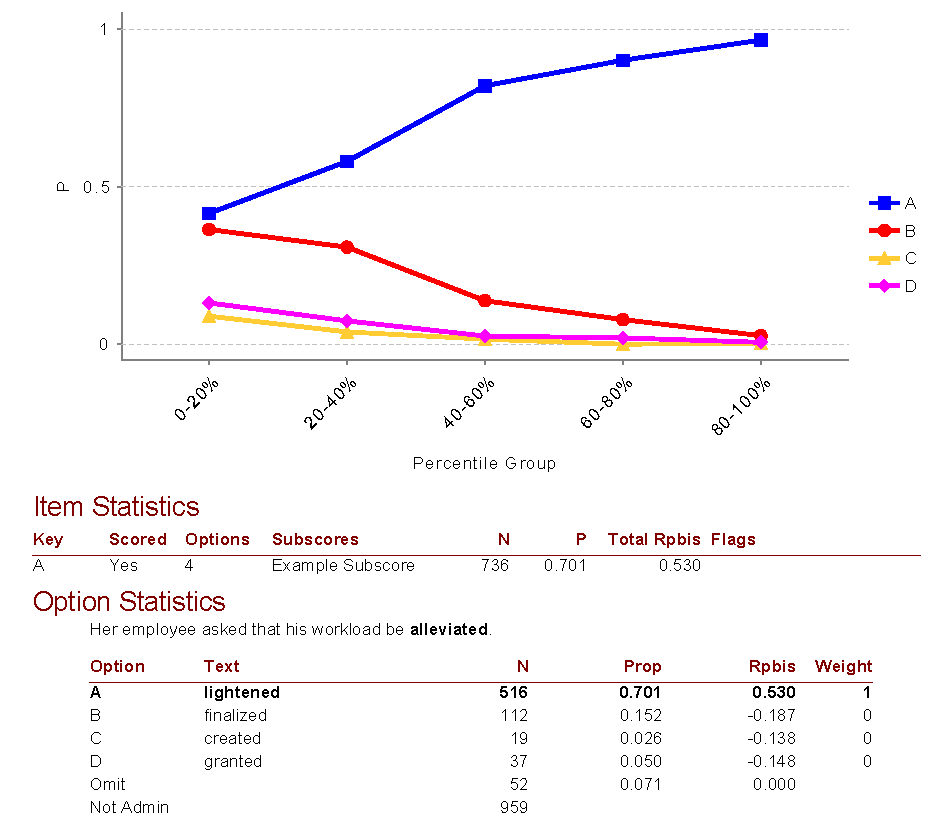
Here is some output from our Iteman software. This is deeply analyzing a single question on English vocabulary, to see if the student knows the word alleviate. About 70% of the students answered correctly, with a very strong point-biserial. The distractor P values were all in the minority and the distractor point-biserials were negative, which adds evidence to the validity. The graph shows that the line for the correct answer is going up while the others are going down, which is good. If you are familiar with item response theory, you’ll notice how the blue line is similar to an item response function. That is not a coincidence.
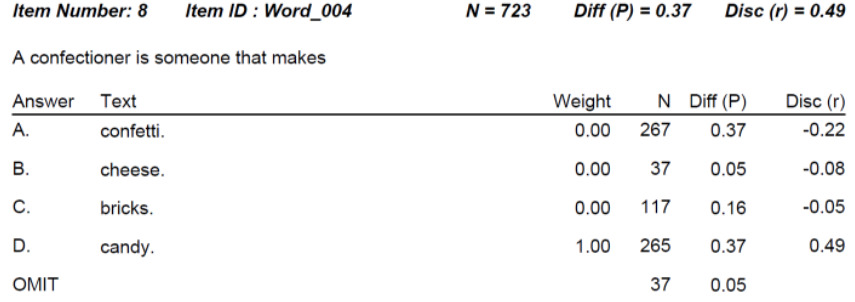
Now, let’s look at another one, which is more interesting. Here’s a vocab question about the word confectioner. Note that only 37% of the students get it right… even though there is a 25% chance just of guessing!!! However, the point-biserial discrimination remains very strong at 0.49. That means it is a really good item. It’s just hard, which means it does a great job to differentiate amongst the top students.
Psychometrics looks fun! How can I join the band?
You will need a graduate degree. I recommend you look at the NCME website with resources for students. Good luck!
Already have a degree and looking for a job? Here’s the two sites that I recommend:
NCME – Also has a job listings page that is really good (ncme.org)
Horizon Search – Headhunter for Psychometricians and I/O Psychologists
Nathan Thompson, PhD
Latest posts by Nathan Thompson, PhD (see all)
- What is a T score? - April 15, 2024
- Item Review Workflow for Exam Development - April 8, 2024
- Likert Scale Items - February 9, 2024





