
In the past decade, terms like machine learning, artificial intelligence, and data mining are becoming greater buzzwords as computing power, APIs, and the massively increased availability of data enable new technologies like self-driving cars. However, we’ve been using methodologies like machine learning in psychometrics for decades. So much of the hype is just hype.
So, what exactly is Machine Learning?
Unfortunately, there is no widely agreed-upon definition, and as Wikipedia notes, machine learning is often conflated with data mining. A broad definition from Wikipedia is that machine learning explores the study and construction of algorithms that can learn from and make predictions on data. It’s often divided into supervised learning, where a researcher drives the process, and unsupervised learning, where the computer is allowed to creatively run wild and look for patterns. The latter isn’t of much use to us, at least yet.
Supervised learning includes specific topics like regression, dimensionality reduction, anomaly detection that we obviously have in Psychometrics. But its the general definition above that really fits what Psychometrics has been doing for decades.
What is Machine Learning in Psychometrics?
We can’t cover all the ways that machine learning and related topics are used in psychometrics and test development, but here’s a sampling. My goal is not to cover them all but to point out that this is old news and that should not get hung up on buzzwords and fads and marketing schticks – but by all means, we should continue to drive in this direction.
Dimensionality Reduction
One of the first, and most straightforward, areas is dimensionality reduction. Given a bunch of unstructured data, how can we find some sort of underlying structure, especially based on latent dimension? We’ve been doing this, utilizing methods like cluster analysis and factor analysis, since Spearman first started investigating the structure of intelligence 100 years ago. In fact, Spearman helped invent those approaches to solve the problems that he was trying to address in psychometrics, which was a new field at the time and had no methodology yet. How seminal was this work in psychometrics for the field of machine learning in general? The Coursera MOOC on Machine Learning uses Spearman’s work as an example in one of the early lectures!
Classification
Classification is a typical problem in machine learning. A common example is classifying images, and the classic dataset is the MNIST handwriting set (though Silicon Valley fans will think of the “not hot dog” algorithm). Given a bunch of input data (image files) and labels (what number is in the image), we develop an algorithm that most effectively can predict future image classification. A closer example to our world is the iris dataset, where several quantitative measurements are used to predict the species of a flower.
The contrasting groups method of setting a test cutscore is a simple example of classification in psychometrics. We have a training set where examinees are already classified as pass/fail by a criterion other than test score (which of course rarely happens, but that’s another story), and use mathematical models to find the cutscore that most efficiently divides them. Not all standard setting methods take a purely statistical approach; understandably, the cutscores cannot be decided by an arbitrary computer algorithm like support vector machines or they’d be subject to immediate litigation. Strong use of subject matter experts and integration of the content itself is typically necessary.
Of course, all tests that seek to assign examinees into categories like Pass/Fail are addressing the classification problem. Some of my earliest psychometric work on the sequential probability ratio test and the generalized likelihood ratio was in this area.
One of the best examples of supervised learning for classification, but much more advanced than the contrasting groups method, is automated essay scoring, which as been around for about 2 decades. It has all the classic trappings: a training set where the observations are classified by humans first, and then mathematical models are trained to best approximate the humans. What makes it more complex is that the predictor data is now long strings of text (student essays) rather than a single number.
Anomaly Detection
The most obvious way this is used in our field is psychometric forensics, trying to find examinees that are cheating or some other behavior that warrants attention. But we also use it to evaluate model fit, possibly removing items or examinees from our data set.
Using Algorithms to Learn/Predict from Data
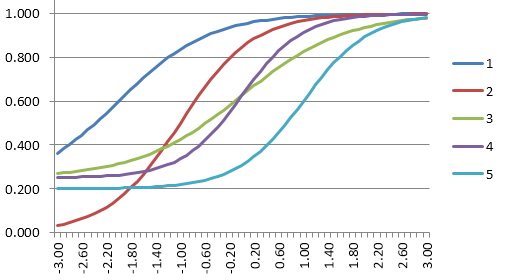 Item response theory is a great example of the general definition. With IRT, we are certainly using a training set, which we call a calibration sample. We use it to train some models, which are then used to make decisions in future observations, primarily scoring examinees that take the test by predicting where those examinees would fall in the score distribution of the calibration sample. IRT is also applied to solve more sophisticated algorithmic problems: Computerized adaptive testing and automated test assembly are fantastic examples. We IRT more generally to learn from the data; which items are most effective, which are not, the ability range where the test provides most precision, etc.
Item response theory is a great example of the general definition. With IRT, we are certainly using a training set, which we call a calibration sample. We use it to train some models, which are then used to make decisions in future observations, primarily scoring examinees that take the test by predicting where those examinees would fall in the score distribution of the calibration sample. IRT is also applied to solve more sophisticated algorithmic problems: Computerized adaptive testing and automated test assembly are fantastic examples. We IRT more generally to learn from the data; which items are most effective, which are not, the ability range where the test provides most precision, etc.
What differs from the Classification problem is that we don’t have a “true state” of labels for our training set. That is, we don’t know what the true scores are of the examinees, or if they are truly a “pass” or a “fail” – especially because those terms can be somewhat arbitrary. It is for this reason we rely on a well-defined model with theoretical reasons for it fitting our data, rather than just letting a machine learning toolkit analyze it with any model it feels like.
Arguably, classical test theory also fits this definition. We have a very specific mathematical model that is used to learn from the data, including which items are stronger or more difficult than others, and how to construct test forms to be statistically equivalent. However, its use of prediction is much weaker. We do not predict where future examinees would fall in the distribution of our calibration set. The fact that it is test-form-specific hampers is generalizability.
Reinforcement learning
The Wikipedia article also mentions reinforcement learning. This is used less often in psychometrics because test forms are typically published with some sort of finality. That is, they might be used in the field for a year or two before being retired, and no data is analyzed in that time except perhaps some high level checks like the NCCA Annual Statistical Report. Online IRT calibration is a great example, but is rarely used in practice. There, response data is analyzed algorithmically over time, and used to estimate or update the IRT parameters. Evaluation of parameter drift also fits in this definition.
Use of Test Scores
We also use test scores “outside” the test in a machine learning approach. A classic example of this is using pre-employment test scores to predict job performance, especially with additional variables to increase the incremental validity. But I’m not going to delve into that topic here.
Automation
Another huge opportunity for machine learning in psychometrics that is highly related is automation. That is, programming computers to do tasks more effectively or efficient than humans. Automated test assembly and automated essay scoring are examples of this, but there are plenty of of ways that automation can help that are less “cool” but have more impact. My favorite is the creation of psychometrics reports; Iteman and Xcalibre do not produce any numbers also available in other software, but they automatically build you a draft report in MS Word, with all the tables, graphs, and narratives already embedded. Very unique. Without that automation, organizations would typically pay a PhD psychometrician to spend hours of time on copy-and-paste, which is an absolute shame. The goal of my mentor, Prof. David Weiss, and myself is to automate the test development cycle as a whole; driving job analysis, test design, item writing, item review, standard setting, form assembly, test publishing, test delivery, and scoring. There’s no reason people should be allowed to continue making bad tests, and then using those tests to ruin people’s lives, when we know so much about what makes a decent test.
Summary
I am sure there are other areas of psychometrics and the testing industry that are soon to be disrupted by technological innovations such as this. What’s next?
As this article notes, the future direction is about the systems being able to learn on their own rather than being programmed; that is, more towards unsupervised learning than supervised learning. I’m not sure how well that fits with psychometrics.
But back to my original point: psychometrics has been a data-driven field since its inception a century ago. In fact, we contributed some of the methodology that is used generally in the field of machine learning and data analytics. So it shouldn’t be any big news when you hear terms like machine learning, data mining, AI, or dimensionality reduction used in our field! In contrast, I think it’s more important to consider how we remove roadblocks to more widespread use.
One of the hurdles we need to overcome for machine learning in psychometrics yet is simply how to get more organizations doing what has been considered best practice for decades. There are two types of problem organizations. The first type is one that does not have the sample sizes or budget to deal with methodologies like I’ve discussed here. The salient example I always think of is a state licensure test required by law for a niche profession that might have only 3 examinees per year (I have talked with such programs!). Not much we can do there. The second type is those organizations that indeed have large sample sizes and a decent budget, but are still doing things the same way they did them 30 years ago. How can we bring modern methods and innovations to these organizations? Because they will definitely only make their tests more effective and fairer.

Nathan Thompson earned his PhD in Psychometrics from the University of Minnesota, with a focus on computerized adaptive testing. His undergraduate degree was from Luther College with a triple major of Mathematics, Psychology, and Latin. He is primarily interested in the use of AI and software automation to augment and replace the work done by psychometricians, which has provided extensive experience in software design and programming. Dr. Thompson has published over 100 journal articles and conference presentations, but his favorite remains https://scholarworks.umass.edu/pare/vol16/iss1/1/ .