Test Development
Item Analysis in Psychometrics: Improve Your Test
Item analysis is the statistical evaluation of test questions to ensure they are good quality, and fix them if they are not. This is a key step in the test development cycle; after items have

Seven Technology Hacks to Deliver Assessments More Securely
So, yeah, the use of “hacks” in the title is definitely on the ironic and gratuitous side, but there is still a point to be made: are you making full use of current technology to
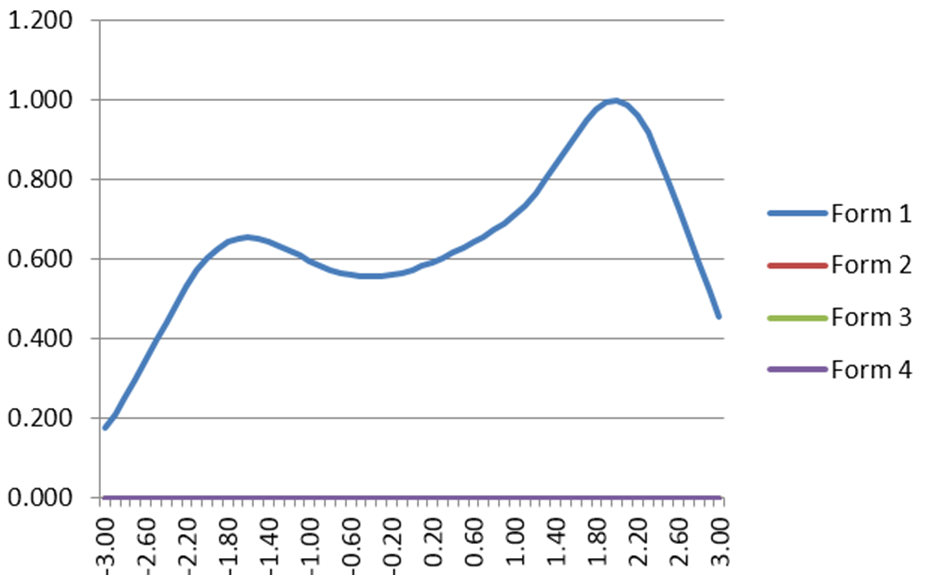
IRT Test Information Function
The IRT Test Information Function is a concept from item response theory (IRT) that is designed to evaluate how well an assessment differentiates examinees, and at what ranges of ability. For example, we might expect

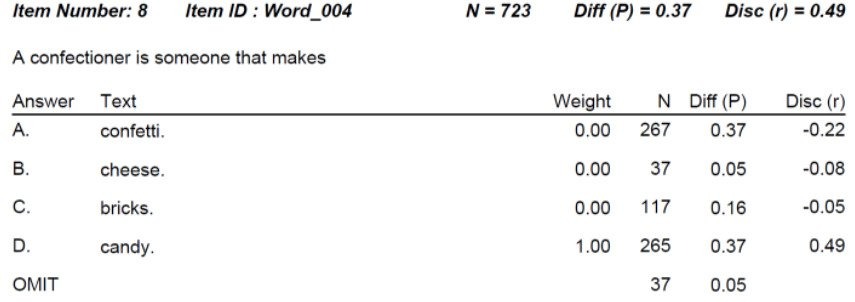
What is Classical Item Difficulty (P Value)?
One of the core concepts in psychometrics is item difficulty. This refers to the probability that examinees will get the item correct for educational/cognitive assessments or respond in the keyed direction with psychological/survey assessments (more on that

What can Machine Learning tell us about our item banks?
Artificial intelligence (AI) and machine learning (ML) have become buzzwords over the past few years. As I already wrote about, they are actually old news in the field of psychometrics. Factor analysis is a classical

Ways the Word “Standard” is used in Assessment
If you have worked in the field of assessment and psychometrics, you have undoubtedly encountered the word “standard.” While a relatively simple word, it has the potential to be confusing because it is used in

Is teaching to the test a bad thing?
One of the most cliche phrases associated with assessment is “teaching to the test.” I’ve always hated this phrase, because it is only used in a derogatory matter, almost always by people who do not

What is classical item facility?
Classical test theory is a century-old paradigm for psychometrics – using quantitative and scientific processes to develop and analyze assessments to improve their quality. (Nobody likes unfair tests!) The most basic and frequently used item
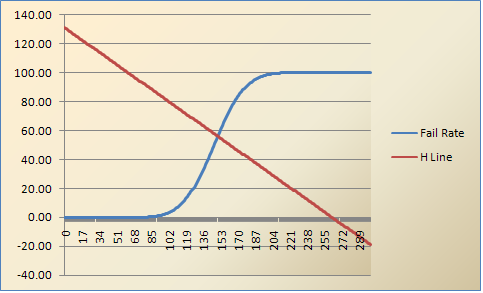
What is the Hofstee method for setting cutscores?
Have you heard about standard setting approaches such as the Hofstee method, or perhaps the Angoff, Ebel, Nedelsky, or Bookmark methods? There are certainly various ways to set a defensible cutscore or a professional credentialing