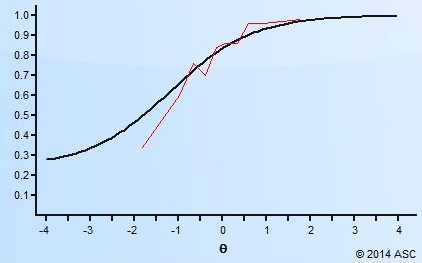
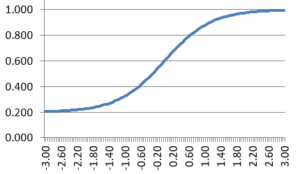
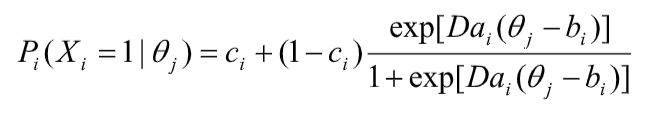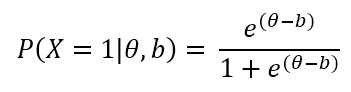Factor analysis is a statistical technique widely used in research to understand and evaluate the underlying structure of assessment data. In fields such as education, psychology, and medicine, this approach to unsupervised machine learning helps researchers and educators identify latent variables, called factors, and which items or tests load on these factors.
For instance, when students take multiple tests, factor analysis can reveal whether these assessments are influenced by common underlying abilities, like verbal reasoning or mathematical reasoning. This insight is crucial for developing reliable and valid assessments, as it helps ensure that test items are measuring the intended constructs. It can also be used to evaluate whether items in an assessment are unidimensional, which is an assumption of both item response theory and classical test theory.
Why Do We Need Factor Analysis?
Factor analysis is a powerful tool for test validation. By analyzing the data, educators and psychometricians can confirm whether the items on a test align with the theoretical constructs they are designed to measure. This ensures that the test is not only reliable but also valid, meaning it accurately reflects the abilities or knowledge it intends to assess. Through this process, factor analysis contributes to the continuous improvement of educational tools, helping to enhance both teaching and learning outcomes.
What is Factor Analysis?
Factor analysis is a comprehensive statistical technique employed to uncover the latent structure underlying a set of observed variables. In the realms of education and psychology, these observed variables are often test scores or scores on individual test items. The primary goal of factor analysis is to identify underlying dimensions, or factors, that explain the patterns of intercorrelations among these variables. By analyzing these intercorrelations, factor analysis helps researchers and test developers understand which variables group together and may be measuring the same underlying construct.
One of the key outputs of factor analysis is the loading table or matrix (see below), which displays the correlations between the observed variables with the latent dimensions, or factors. These loadings indicate how strongly each variable is associated with a particular factor, helping to reveal the structure of the data. Ideally, factor analysis aims to achieve a “simple structure,” where each variable loads highly on one factor and has minimal loadings on others. This clear pattern makes it easier to interpret the results and understand the underlying constructs being measured. By providing insights into the relationships between variables, factor analysis is an essential tool in test development and validation, helping to ensure that assessments are both reliable and valid.
Confirmatory vs. Exploratory Factor Analysis
Factor analysis comes in two main forms: Confirmatory Factor Analysis (CFA) and Exploratory Factor Analysis (EFA), each serving distinct purposes in research.
Exploratory Factor Analysis (EFA) is typically used when researchers have little to no prior knowledge about the underlying structure of their data. It is a data-driven approach that allows researchers to explore the potential factors that emerge from a set of observed variables. In EFA, the goal is to uncover patterns and identify how many latent factors exist without imposing any preconceived structure on the data. This approach is often used in the early stages of research, where the objective is to discover the underlying dimensions that might explain the relationships among variables.
On the other hand, Confirmatory Factor Analysis (CFA) is a hypothesis-driven approach used when researchers have a clear theoretical model of the factor structure they expect to find. In CFA, researchers specify the number of factors and the relationships between the observed variables and these factors before analyzing the data. The primary goal of CFA is to test whether the data fit the hypothesized model. This approach is often used in later stages of research or in validation studies, where the focus is on confirming the structure that has been previously identified or theoretically proposed. By comparing the model fit indices, researchers can determine how well their proposed factor structure aligns with the actual data, providing a more rigorous test of their hypotheses.
Factor Analysis of Test Batteries or Sections, or Multiple Predictors
Factor analysis is particularly valuable when dealing with test batteries, which are collections of tests designed to measure various aspects of student cognitive abilities, skills, or knowledge. In the context of a test battery, factor analysis helps to identify the underlying structure of the tests and determine whether they measure distinct yet related constructs.
For example, a cognitive ability test battery might include subtests for verbal reasoning, quantitative reasoning, and spatial reasoning. Through factor analysis, researchers can examine how these subtests correlate and whether they load onto separate factors, indicating they measure distinct abilities, or onto a single factor, suggesting a more general underlying ability, often referred to as the “g factor” or general intelligence.
This approach can also incorporate non-assessment data. For example a researcher on employee selection might look at a set of assessments (cognitive ability, job knowledge, quantitative reasoning, MS Word skills, integrity, counterproductive work behavior), but also variables such as interview scores or resume ratings. Below is an oversimplified example of how the loading matrix might look for this.
Table 1
| Variable | Dimension 1 | Dimension 2 |
| Cognitive ability | 0.42 | 0.09 |
| Job knowledge | 0.51 | 0.02 |
| Quantitative reasoning | 0.36 | -0.02 |
| MS Word skills | 0.49 | 0.07 |
| Integrity | 0.03 | 0.26 |
| Counterproductive work behavior | -0.01 | 0.31 |
| Interview scores | 0.16 | 0.29 |
| Resume ratings | 0.11 | 0.12 |
Readers that are familiar with the topic will recognize this as a nod to the work by Walter Borman and Steve Motowidlo on Task vs. Contextual aspects of job performance. A variable like Job Knowledge would load highly on a factor of task aspects of performing a job. However, an assessment of counterproductive work behavior might not predict how well they do tasks, but how well they contribute to company culture and other contextual aspects.
This analysis is crucial for ensuring that the test battery provides comprehensive and valid measurements of the constructs it aims to assess. By confirming that each subtest contributes unique information, factor analysis supports the interpretation of composite scores and aids in the design of more effective assessment tools. The process of validating test batteries is essential to maintain the integrity and utility of the test results in educational and psychological settings.
This approach typically uses “regular” factor analysis, which assumes that scores for each input variable are normally distributed. This, of course, is usually the case with something like scores on an intelligence test. But if you are analyzing scores on test items, these are rarely normally distributed, especially for dichotomous data where there is only possible scores of 0 and 1, this is impossible. Therefore, other mathematical approaches must be applied.
Factor Analysis on the Item Level
Factor analysis at the item level is a more granular approach, focusing on the individual test items rather than entire subtests or batteries. This method is used to ensure that each item contributes appropriately to the overall construct being measured and to identify any items that do not align well with the intended factors.
For instance, in a reading comprehension test, factor analysis at the item level can reveal whether each question accurately measures the construct of reading comprehension or whether some items are more aligned with other factors, such as vocabulary knowledge or reasoning skills. Items that do not load strongly onto the intended factor may be flagged for revision or removal, as they could distort the accuracy of the test scores.
This item-level analysis is crucial for developing high-quality educational or knowledge assessments, as it helps to ensure that every question is both valid and reliable, contributing meaningfully to the overall test score. It also aids in identifying “enemy items,” which are questions that could undermine the test’s consistency and fairness.
Similarly, in personality assessments like the Big Five Personality Test, factor analysis is used to confirm the structure of personality traits, ensuring that the test accurately captures the five broad dimensions: openness, conscientiousness, extraversion, agreeableness, and neuroticism. This process ensures that each trait is measured distinctly while also considering how they may interrelate. Note that the result here was not to show overall unidimensionality in personality, but evidence to support five factors. An assessment of a given factor is then more or less unidimensional.
An example of this is show in Table 2 below. Consider if all the descriptive statements are items in a survey where people rate them on a Likert scale of 1 to 5. The survey might have hundreds of adjectives but these would align themselves with the Big Five with factor analysis, and the simple structure would look like something you see below (2 items per factor in this small example).
Table 2
| Statement | Dimension 1 | Dimension 2 | Dimension 3 | Dimension 4 | Dimension 5 |
| I like to try new things | 0.63 | 0.02 | 0.00 | -0.03 | -0.02 |
| I enjoy exciting sports | 0.71 | 0.00 | 0.11 | -0.08 | 0.07 |
| I consider myself neat and tidy | 0.02 | 0.56 | 0.08 | 0.11 | 0.08 |
| I am a perfectionist | -0.05 | 0.69 | -0.08 | 0.09 | -0.09 |
| I like to go to parties | 0.11 | 0.15 | 0.74 | 0.08 | 0.00 |
| I prefer to spend my free time alone (reverse scored) | 0.13 | 0.07 | 0.81 | 0.01 | 0.05 |
| I tend to “go with the flow” | -0.14 | 0.02 | -0.04 | 0.68 | 0.08 |
| I enjoy arguments and debates (reverse scored) | 0.03 | -0.04 | -0.05 | 0.72 | 0.11 |
| I get stressed out easily (reverse scored) | -0.05 | 0.03 | 0.03 | 0.05 | 0.81 |
| I perform well under pressure | 0.02 | 0.02 | 0.02 | -0.01 | 0.77 |
Tools like MicroFACT, a specialized software for evaluating unidimensionality, are invaluable in this process. MicroFACT enables psychometricians to assess whether each item in a test measures a single underlying construct, ensuring the test’s coherence and effectiveness.
Summary
Factor analysis plays a pivotal role in the field of psychometrics, offering deep insights into the structure and validity of educational assessments. Whether applied to test batteries or individual items, factor analysis helps ensure that tests are both reliable and meaningful.
Overall, factor analysis is indispensable for developing effective educational tools and improving assessment practices. It ensures that tests not only measure what they are supposed to but also do so in a way that is fair and consistent across different groups and over time. As educational assessments continue to evolve, the insights provided by factor analysis will remain crucial in maintaining the integrity and effectiveness of these tools.
References
Geisinger, K. F., Bracken, B. A., Carlson, J. F., Hansen, J.-I. C., Kuncel, N. R., Reise, S. P., & Rodriguez, M. C. (Eds.). (2013). APA handbook of testing and assessment in psychology, Vol. 1. Test theory and testing and assessment in industrial and organizational psychology. American Psychological Association. https://doi.org/10.1037/14047-000
Kline, R. B. (2015). Principles and practice of structural equation modeling (4th ed.). The Guilford Press.
Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric theory (3rd ed.). Tata Mcgraw-Hill Ed.