Test score reliability and validity are core concepts in the field of psychometrics and assessment. Both of them refer to the quality of a test, the scores it produces, and how we use those scores. Because test scores are often used for very important purposes with high stakes, it is of course paramount that the tests be of high quality. But because it is such a complex situation, it is not a simple yes/no answer of whether a test is good. There is a ton of work that goes into establishing validity and reliability, and that work never ends!
This post provide an introduction to this incredibly complex topic. For more information, we recommend you delve into books that are dedicated to the topic. Here is a classic.
Why do we need reliability and validity?
To begin a discussion of reliability and validity, let us first pose the most fundamental question in psychometrics: Why are we testing people? Why are we going through an extensive and expensive process to develop examinations, inventories, surveys, and other forms of assessment? The answer is that the assessments provide information, in the form of test scores and subscores, that can be used for practical purposes to the benefit of individuals, organizations, and society. Moreover, that information is of higher quality for a particular purpose than information available from alternative sources. For example, a standardized test can provide better information about school students than parent or teacher ratings. A preemployment test can provide better information about specific job skills than an interview or a resume, and therefore be used to make better hiring decisions.
So, exams are constructed in order to draw conclusions about examinees based on their performance. The next question would be, just how supported are various conclusions and inferences we are making? What evidence do we have that a given standardized test can provide better information about school students than parent or teacher ratings? This is the central question that defines the most important criterion for evaluating an assessment process: validity. Validity, from a broad perspective, refers to the evidence we have to support a given use or interpretation of test scores. The importance of validity is so widely recognized that it typically finds its way into laws and regulations regarding assessment (Koretz, 2008).
Test score reliability is a component of validity. Reliability indicates the degree to which test scores are stable, reproducible, and free from measurement error. If test scores are not reliable, they cannot be valid since they will not provide a good estimate of the ability or trait that the test intends to measure. Reliability is therefore a necessity but not sufficient condition for validity.
Test Score Reliability
Reliability refers to the precision, accuracy, or repeatability of the test scores. There is no universally accepted way to define and evaluate the concept; classical test theory provides several indices, while item response theory drops the idea of a single index (and drops the term “reliability” entirely!) and reconceptualizes it as a conditional standard error of measurement, an index of precision. This is actually a very important distinction, though outside the scope of this article.
An extremely common way of evaluating classical test reliability is the internal consistency index, called KR-20 or α (alpha). The KR-20 index ranges from 0.0 (test scores are comprised only of random error) to 1.0 (scores have no measurement error). Of course, because human behavior is generally not perfectly reproducible, perfect reliability is not possible; typically, a reliability of 0.90 or higher is desired for high-stakes certification exams. The relevant standard for a test depends on its stakes. A test for medical doctors might require reliability of 0.95 or greater. A test for florists or a personality self-assessment might suffice with 0.80. Another method for assessing reliability is the Split Half Reliability Index, which can also be useful depending on the context and nature of the test.
Reliability depends on several factors, including the stability of the construct, length of the test, and the quality of the test items.
- Stability of the construct: Reliability will be higher if the trait/ability is more stable (mood is inherently difficult to measure repeatedly). A test sponsor typically has little control over the nature of the construct – if you need to measure knowledge of algebra, well, that’s what we have to measure, and there’s no way around that.
- Length of the test: Obviously, a test with 100 items is going to produce better scores than one with 5 items, assuming the items are not worthless.
- Item Quality: A test will have higher reliability if the items are good. Often, this is operationalized as point-biserial discrimination coefficients.
How to you calculate reliability? You need psychometric analysis software like Iteman.
Validity
Validity is conventionally defined as the extent to which a test measures what it purports to measure. Test validation is the process of gathering evidence to support the inferences made by test scores. Validation is an ongoing process which makes it difficult to know when one has reached a sufficient amount of validity evidence to interpret test scores appropriately.
Academically, Messick (1989) defines validity as an “integrated evaluative judgment of the degree to which empirical evidence and theoretical rationales support the adequacy and appropriateness of inferences and actions based on test scores or other modes of measurement.” This definition suggests that the concept of validity contains a number of important characteristics to review or propositions to test and that validity can be described in a number of ways. The modern concept of validity (AERA, APA, & NCME Standards) is multi-faceted and refers to the meaningfulness, usefulness, and appropriateness of inferences made from test scores.
First of all, validity is not an inherent characteristic of a test. It is the reasonableness of using the test score for a particular purpose or for a particular inference. It is not correct to say a test or measurement procedure is valid or invalid. It is more reasonable to ask, “Is this a valid use of test scores or is this a valid interpretation of the test scores?” Test score validity evidence should always be reviewed in relation to how test scores are used and interpreted. Example: we might use a national university admissions aptitude test as a high school graduation exam, since they occur in the same period of a student’s life. But it is likely that such a test does not match the curriculum of a particular state, especially since aptitude and achievement are different things! You could theoretically use the aptitude test as a pre-employment exam as well; while valid in its original use it is likely not valid in that use.
Secondly, validity cannot be adequately summarized by a single numerical index like a reliability coefficient or a standard error of measurement. A validity coefficient may be reported as a descriptor of the strength of relationship between other suitable and important measurements. However, it is only one of many pieces of empirical evidence that should be reviewed and reported by test score users. Validity for a particular test score use is supported through an accumulation of empirical, theoretical, statistical, and conceptual evidence that makes sense for the test scores.
Thirdly, there can be many aspects of validity dependent on the intended use and intended inferences to be made from test scores. Scores obtained from a measurement procedure can be valid for certain uses and inferences and not valid for other uses and inferences. Ultimately, an inference about probable job performance based on test scores is usually the kind of inference desired in test score interpretation in today’s test usage marketplace. This can take the form of making an inference about a person’s competency measured by a tested area.
Example 1: A Ruler
A standard ruler has both reliability and validity. If you measure something that is 10 cm long, and measure it again and again, you will get the same measurement. It is highly consistent and repeatable. And if the object is actually 10 cm long, you have validity. (If not, you have a bad ruler.)
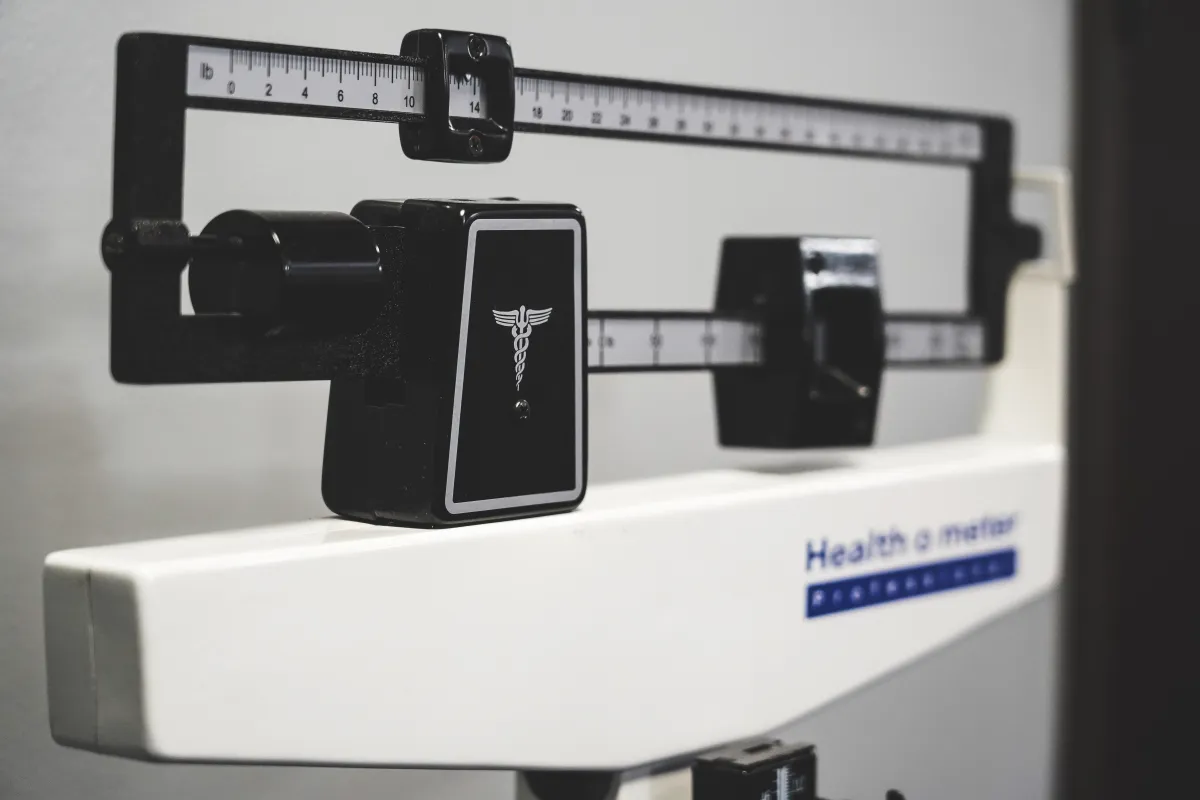
Example 2: A Bathroom Scale
Bathroom scales are not perfectly reliable (though this is often a function of their price). But that meets the reliability requirements of this measurement.
- If you weigh 180 lbs, and step on the scale several times, you will likely get numbers like 179.8 or 180.1. That is quite reliable, and valid.
- If the numbers were more spread out, like 168.9 and 185.7, then you can consider it unreliable but valid.
- If the results were 190.00 lbs every time, you have perfectly reliable measurement… but poor validity
- If the results were spread like 25.6, 2023.7, 0.000053 – then it is neither reliable or valid.
This is similar to the classic “target” example of reliability and validity, like you see below (image from Wikipedia).
Example 3: A Pre-Employment Test
Now, let’s get to a real example. You have a test of quantitative reasoning that is being used to assess bookkeepers that apply for a job at a large company. Jack has very high ability, and scores around the 90th percentile each time he takes the test. This is reliability. But does it actually predict job performance? That is validity. Does it predict job performance better than a Microsoft Excel test? Good question, time for some validity research. What if we also tack on a test of conscientiousness? That is incremental validity.
Summary
In conclusion, validity and reliability are two essential aspects in evaluating an assessment, be it an examination of knowledge, a psychological inventory, a customer survey, or an aptitude test. Validity is an overarching, fundamental issue that drives at the heart of the reason for the assessment in the first place: the use of test scores. Reliability is an aspect of validity, as it is a necessary but not sufficient condition. Developing a test that produces reliable scores and valid interpretations is not an easy task, and progressively higher stakes indicate a progressively greater need for a professional psychometrician. High-stakes exams like national university admissions often have teams of experts devoted to producing a high quality assessment.
If you need professional psychometric consultancy and support, do not hesitate to contact us.

Nathan Thompson earned his PhD in Psychometrics from the University of Minnesota, with a focus on computerized adaptive testing. His undergraduate degree was from Luther College with a triple major of Mathematics, Psychology, and Latin. He is primarily interested in the use of AI and software automation to augment and replace the work done by psychometricians, which has provided extensive experience in software design and programming. Dr. Thompson has published over 100 journal articles and conference presentations, but his favorite remains https://scholarworks.umass.edu/pare/vol16/iss1/1/ .