Las pruebas adaptativas computarizadas (PAC) son un enfoque de evaluación basado en IA donde la prueba se personaliza en función de su desempeño a medida que realiza la prueba, lo que hace que la prueba sea más corta, más precisa, más segura, más atractiva y más justa. Si le va bien, los elementos se vuelven más difíciles y, si le va mal, los elementos se vuelven más fáciles. Si se alcanza una puntuación precisa, la prueba se detiene antes. Al adaptar la dificultad de las preguntas al desempeño de cada examinado, PAC garantiza un proceso de prueba eficiente y seguro.
Los algoritmos de IA casi siempre se basan en la teoría de respuesta al ítem (TRI), una aplicación del aprendizaje automático a la evaluación, pero también pueden basarse en otros modelos.
¿Prefieres aprender haciendo? Solicite una cuenta gratuita en FastTest, nuestra poderosa plataforma de pruebas adaptativas.
¿Qué son las pruebas adaptativas computarizadas?
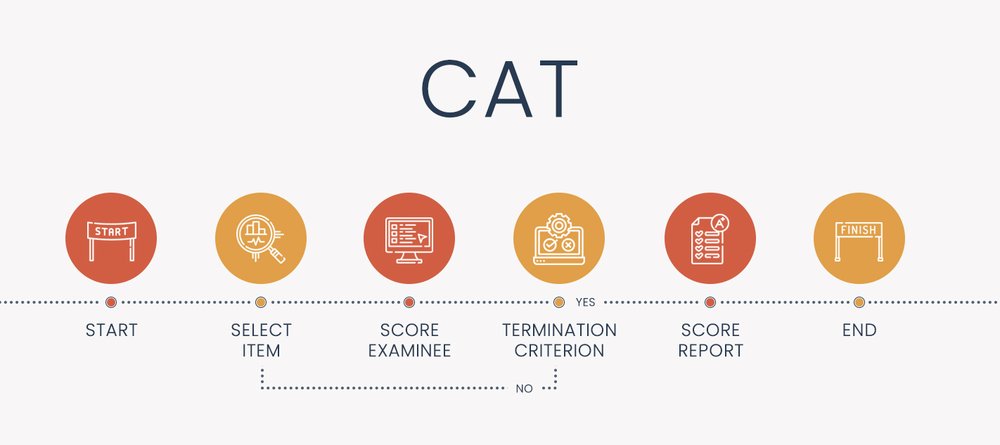
Las pruebas adaptativas computarizadas (PAC), a veces llamadas pruebas adaptativas por computadora, evaluación adaptativa o pruebas adaptativas, son un algoritmo que personaliza cómo se entrega una evaluación a cada examinado. Está codificada en una plataforma de software, utilizando el enfoque de aprendizaje automático de TRI para seleccionar elementos y calificar a los examinados. El algoritmo procede en un bucle hasta que se completa la prueba. Esto hace que la prueba sea más inteligente, más corta, más justa y más precisa.
Los pasos del diagrama anterior están adaptados de Kingsbury y Weiss (1984) en función de estos componentes.
Componentes de una pruebas adaptativas computarizadas
- Banco de ítems calibrado con TRI
- Punto de inicio (nivel theta antes de que alguien responda un ítem)
- Algoritmo de selección de ítems (normalmente, máxima información de Fisher)
- Método de puntuación (p. ej., máxima verosimilitud)
- Criterio de finalización (¿detener la prueba en 50 ítems o cuando el error estándar sea inferior a 0,30? ¿Ambos?)
Cómo funcionan los componentes
Para empezar, necesitas un banco de ítems que haya sido calibrado con un modelo psicométrico o de aprendizaje automático relevante. Es decir, no puedes simplemente escribir unos pocos ítems y clasificarlos subjetivamente como de dificultad Fácil, Media o Difícil. Esa es una forma fácil de ser demandado. En cambio, necesitas escribir una gran cantidad de ítems (la regla general es 3 veces la duración prevista de la prueba) y luego probarlos en una muestra representativa de examinados. La muestra debe ser lo suficientemente grande para soportar el modelo psicométrico que elijas, y puede variar de 100 a 1000. Luego necesitas realizar una investigación de simulación (más sobre eso más adelante).
Una vez que tenga un banco de elementos listo, así es como funciona el algoritmo de prueba adaptativa computarizada para un estudiante que se sienta a tomar la prueba, con opciones sobre cómo hacerlo.
- Punto de partida: hay tres opciones para seleccionar la puntuación inicial, que los psicometristas llaman theta
- Todos obtienen el mismo valor, como 0,0 (promedio, en el caso de modelos que no son Rasch)
- Aleatorizado dentro de un rango, para ayudar a probar la seguridad y la exposición del artículo
- Valor previsto, tal vez a partir de datos externos o de un examen anterior
- Seleccionar artículo
- Encuentra el elemento en el banco que tenga el mayor valor informativo
- A menudo, es necesario equilibrar esto con restricciones prácticas, como la exposición del artículo o el equilibrio del contenido.
- Calificar al examinado
- Generalmente IRT, máxima verosimilitud o modal bayesiano
- Evaluar el criterio de terminación: utilizando una regla predefinida respaldada por su investigación de simulación
- ¿Se alcanza un cierto nivel de precisión, como un error estándar de medición < 0,30?
- ¿No quedan artículos buenos en el banco?
- ¿Se alcanzó un límite de tiempo?
- ¿Se ha alcanzado el límite máximo de artículos?
El algoritmo funciona repitiendo los pasos 2-3-4 hasta que se satisface el criterio de terminación.
¿Cómo se adapta la prueba? ¿Por dificultad o cantidad?
Las PAC funcionan adaptando tanto la dificultad como la cantidad de elementos que ve cada examinado.
Dificultad
La mayoría de las caracterizaciones de las pruebas adaptativas computarizadas se centran en cómo se combina la dificultad de los elementos con la capacidad del examinado. Los examinados de alta capacidad reciben elementos más difíciles, mientras que los de baja capacidad reciben elementos más fáciles, lo que tiene importantes beneficios para el estudiante y la organización. Una prueba adaptativa generalmente comienza entregando un elemento de dificultad media; si lo responde correctamente, recibe un elemento más difícil, y si lo responde incorrectamente, recibe un elemento más fácil. Este patrón continúa.
Cantidad: longitud fija frente a longitud variable
Una faceta menos publicitada de la adaptación es la cantidad de elementos. Las pruebas adaptativas pueden diseñarse para detenerse cuando se alcanzan ciertos criterios psicométricos, como un nivel específico de precisión de la puntuación. Algunos examinados terminan muy rápidamente con pocos elementos, por lo que las pruebas adaptativas suelen tener aproximadamente la mitad de preguntas que una prueba regular, con al menos la misma precisión. Dado que algunos examinados tienen exámenes más largos, estos exámenes adaptativos se denominan de duración variable. Obviamente, esto supone un beneficio enorme: reducir el tiempo de examen a la mitad, en promedio, puede reducir sustancialmente los costos de los exámenes.
Algunas pruebas adaptativas utilizan una duración fija y solo adaptan la dificultad de los ítems. Esto es simplemente por cuestiones de relaciones públicas, es decir, la incomodidad de tratar con examinados que sienten que fueron tratados injustamente por el PAC, a pesar de que se podría decir que es más justo y válido que las pruebas convencionales. En general, es una mejor práctica fusionar los dos: permitir que la duración de la prueba sea más corta o más larga, pero poner límites en cada extremo que eviten pruebas inadvertidamente demasiado cortas o pruebas que potencialmente podrían llegar a 400 ítems. Por ejemplo, el NCLEX tiene un examen de duración mínima de 75 ítems y el examen de duración máxima de 145 ítems.
Ejemplo de algoritmo de prueba adaptativa computarizada
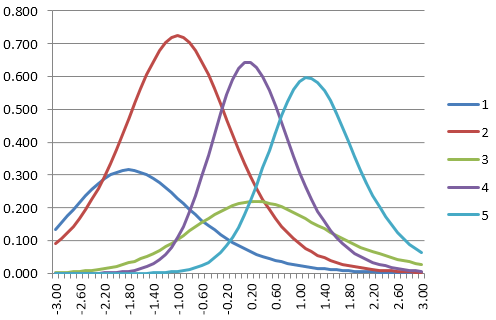
Veamos un ejemplo muy simplificado. Aquí tenemos un banco de preguntas con 5 preguntas. Comenzaremos con una pregunta de dificultad promedio y responderemos como lo haría un estudiante con una dificultad por debajo del promedio.
A continuación se muestran las funciones de información de las preguntas para cinco preguntas de un banco. Supongamos que la theta inicial es 0,0.
- Encontramos el primer elemento a entregar. ¿Qué elemento tiene la información más alta en 0.0? Es el elemento 4.
- Supongamos que el estudiante responde incorrectamente.
- Ejecutamos el algoritmo de puntuación IRT y suponemos que la puntuación es -2.0.
- Comprobamos el criterio de terminación; ciertamente no hemos terminado todavía, después de 1 elemento.
- Encontramos el siguiente elemento. ¿Cuál tiene la información más alta en -2.0? Elemento 2.
- Supongamos que el estudiante responde correctamente.
- Ejecutamos el algoritmo de puntuación IRT y suponemos que la puntuación es -0.8.
- Evaluamos el criterio de terminación; aún no hemos terminado.
- Encontramos el siguiente elemento. El elemento 2 es el más alto en -0.8 pero ya lo usamos. El elemento 4 es el siguiente mejor, pero ya lo usamos. Entonces, el siguiente mejor es el elemento 1.
- El elemento 1 es muy fácil, por lo que el estudiante lo responde correctamente.
- La nueva puntuación es -0.2.
- El mejor elemento restante con -0,2 es el elemento 3.
- Supongamos que el estudiante responde incorrectamente.
- La nueva puntuación es quizás -0,4.
- Evalúa el criterio de finalización. Supón que la prueba tiene un máximo de 3 elementos, un criterio extremadamente simple. Lo hemos cumplido. La prueba ya está hecha y se envió automáticamente.
Ventajas de las pruebas adaptativas informatizadas
Al hacer que la prueba sea más inteligente, las pruebas adaptativas brindan una amplia gama de beneficios. A continuación, se enumeran algunas de las ventajas conocidas de las pruebas adaptativas, reconocidas por la investigación psicométrica académica.
Pruebas más cortas
Las investigaciones han demostrado que las pruebas adaptativas producen una reducción de entre el 50% y el 90% en la duración de la prueba. Esto no es ninguna sorpresa. Supongamos que tienes un conjunto de 100 ítems. Un estudiante destacado tiene prácticamente garantizado que responderá correctamente las 70 preguntas más fáciles; solo las 30 más difíciles le harán pensar. Lo mismo ocurre con un estudiante de bajo nivel. Los estudiantes de nivel medio no necesitan las preguntas superdifíciles ni las superfáciles.
¿Por qué es importante esto? Principalmente, puede reducir en gran medida los costos. Supongamos que estás realizando 100.000 exámenes al año en centros de evaluación y pagas 30 dólares la hora. Si puedes reducir la duración de tu examen de 2 horas a 1 hora, acabas de ahorrar 3.000.000 de dólares. Sí, habrá mayores costos por el uso de la evaluación adaptativa, pero es probable que ahorres dinero al final.
Para la evaluación K12, no estás pagando por el tiempo de asiento, pero existe el costo de oportunidad del tiempo de instrucción perdido. Si los estudiantes toman evaluaciones formativas 3 veces al año para verificar el progreso, y puedes reducir cada una en 20 minutos, es decir 1 hora; si hay 500,000 estudiantes en tu estado, entonces acabas de ahorrar 500,000 horas de aprendizaje.
Puntuaciones más precisas
CAT hará que las pruebas sean más precisas, en general. Esto se logra diseñando los algoritmos específicamente en torno a cómo obtener puntuaciones más precisas sin perder el tiempo del examinado.
Más control de la precisión de la puntuación (exactitud)
CAT garantiza que todos los estudiantes tendrán la misma precisión, lo que hace que la prueba sea mucho más justa. Las pruebas tradicionales miden bien a los estudiantes intermedios, pero no a los mejores o peores. ¿Es mejor que A) los estudiantes ven los mismos elementos pero pueden tener una precisión de puntuación drásticamente diferente, o B) tener una precisión de puntuación equivalente, pero ver elementos diferentes?
Mayor seguridad de la prueba
Dado que todos los estudiantes reciben esencialmente una evaluación que está diseñada para ellos, hay una mayor seguridad de la prueba que si todos ven los mismos 100 elementos. La exposición a los elementos se reduce en gran medida; sin embargo, tenga en cuenta que esto presenta sus propios desafíos y los algoritmos de evaluación adaptativos tienen consideraciones de su propia exposición a los elementos.
Una mejor experiencia para los examinados, con menos fatiga
Las evaluaciones adaptativas tenderán a ser menos frustrantes para los examinados en todos los rangos de habilidad. Además, al implementar reglas de detención de longitud variable (por ejemplo, una vez que sabemos que eres un estudiante destacado, no te damos los 70 ítems fáciles), se reduce la fatiga.
Mayor motivación del examinado
Dado que los examinados solo ven los ítems que son relevantes para ellos, esto proporciona un desafío apropiado. Los examinados de baja habilidad se sentirán más cómodos y obtendrán muchos más ítems correctos que con una prueba lineal. Los estudiantes de alta habilidad obtendrán los ítems difíciles que los hagan pensar.
Es posible volver a realizar pruebas con frecuencia
La idea de la “forma única” se aplica al mismo estudiante que toma el mismo examen dos veces. Supongamos que tomas la prueba en septiembre, al comienzo de un año escolar, y tomas la misma nuevamente en noviembre para verificar tu aprendizaje. Es probable que hayas aprendido bastante y estés más arriba en el rango de habilidad; tendrás ítems más difíciles y, por lo tanto, una nueva prueba. Si fuera una prueba lineal, podría ver exactamente la misma prueba.
Esta es una de las principales razones por las que la evaluación adaptativa desempeña un papel formativo en la educación K-12, y se realiza varias veces al año a millones de estudiantes solo en los Estados Unidos.
Ritmo individual de las pruebas
Los examinados pueden avanzar a su propio ritmo. Algunos pueden avanzar rápidamente y terminar con solo 30 ítems. Otros pueden dudar, también ver 30 ítems pero tomar más tiempo. Aún así, otros pueden ver 60 ítems. Los algoritmos pueden diseñarse para maximizar el proceso.
Ventajas de las pruebas computarizadas en general
Por supuesto, las ventajas de usar una computadora para realizar una prueba también son relevantes. A continuación, se presentan algunas
- Informe de puntaje inmediato
- Las pruebas a pedido pueden reducir la impresión, la programación y otras preocupaciones basadas en papel
- Almacenar los resultados en una base de datos de inmediato facilita la gestión de datos
- Las pruebas computarizadas facilitan el uso de multimedia en los ítems
- Puede ejecutar informes psicométricos de inmediato
- Los plazos se reducen con un sistema de banco de ítems integrado
Cómo desarrollar una evaluación adaptativa que sea válida y defendible
Las PAC son el futuro de la evaluación. Funcionan adaptando tanto la dificultad como la cantidad de ítems a cada examinado individual. El desarrollo de una prueba adaptativa no es una tarea fácil y requiere cinco pasos que integren la experiencia de los desarrolladores de contenido de pruebas, ingenieros de software y psicometristas.
El desarrollo de una prueba adaptativa de calidad es complejo y requiere psicometristas experimentados tanto en calibración de la teoría de respuesta al ítem (TRI) como en investigación de simulación PAC. FastTest puede proporcionarle el psicometrista y el software; si proporciona ítems de prueba y datos piloto, podemos ayudarlo a publicar rápidamente una versión adaptativa de su prueba.
Paso 1: Estudios de viabilidad, aplicabilidad y planificación. Primero, debe realizarse una investigación exhaustiva de simulación de Monte Carlo y los resultados deben formularse como casos de negocios para evaluar si las pruebas adaptativas son factibles, aplicables o incluso posibles.
Paso 2: Desarrollar un banco de ítems. Se debe desarrollar un banco de ítems para cumplir con las especificaciones recomendadas en el Paso 1.
Paso 3: Realizar pruebas previas y calibrar el banco de ítems. Los ítems deben probarse de manera piloto en 200 a 1000 examinados (dependiendo del modelo de TRI) y ser analizados por un psicometrista con doctorado.
Paso 4: Determinar las especificaciones para la PAC final. Los datos del Paso 3 se analizan para evaluar las especificaciones de la PAC y determinar los algoritmos más eficientes utilizando software de simulación de PAC como CATSim.
Paso 5: Publicar la PAC en vivo. La prueba adaptativa se publica en un motor de pruebas capaz de realizar pruebas totalmente adaptativas basadas en TRI. No hay muchos de ellos en el mercado. ¡Regístrese para obtener una cuenta gratuita en nuestra plataforma FastTest y pruébelo usted mismo!
¿Quiere obtener más información sobre nuestro modelo único? Haga clic aquí para leer el artículo fundamental de nuestros dos cofundadores. Hay más investigaciones sobre pruebas adaptativas disponibles aquí.
Requisitos mínimos para las pruebas adaptativas computarizadas
A continuación, se indican algunos requisitos mínimos que debe evaluar si está considerando adoptar el enfoque PAC.
- Un gran banco de ítems probado de modo que cada ítem tenga al menos 100 respuestas válidas (modelo Rasch) o 500 (modelo 3PL)
- 500 examinados por año
- Software especializado de calibración TRI y simulación PAC como Xcalibre y CATSim.
- Personal con un doctorado en psicometría o un nivel equivalente de experiencia. O aproveche nuestra experiencia reconocida internacionalmente en el campo.
- Ítems (preguntas) que se puedan calificar objetivamente como correctos/incorrectos en tiempo real
- Un sistema de banco de ítems y una plataforma de entrega PAC
- Recursos financieros: debido a que es tan complejo, el desarrollo de un PAC costará al menos $10,000 (USD), pero si está evaluando grandes volúmenes de examinados, será una inversión significativamente positiva. Si pagas $20/hora para supervisar los asientos y reduces la duración de un examen de 2 horas a 1 hora para solo 1000 examinados… eso es un ahorro de $20 000. ¿Y si estás haciendo 200 000 exámenes? Eso es un ahorro de $4 000 000 en tiempo de asiento.
Pruebas adaptativas: recursos para leer más
Visite los enlaces a continuación para obtener más información sobre la evaluación adaptativa.
- Primero le recomendamos que lea este artículo fundamental de nuestros cofundadores.
- Lea este artículo sobre cómo producir mejores mediciones con PAC del profesor David J. Weiss.
- Asociación Internacional para Pruebas Adaptativas Computarizadas: www.iacat.org
- A continuación, se incluye el enlace al seminario web sobre la historia de PAC, a cargo del padrino de PAC, el profesor David J. Weiss.
Ejemplos las pruebas adaptativas computarizadas
Muchas evaluaciones a gran escala utilizan tecnología adaptativa. El GRE (Graduate Record Examinations) es un excelente ejemplo de una prueba adaptativa. También lo es el NCLEX (examen de enfermería en los EE. UU.), el GMAT (admisión a escuelas de negocios) y muchas evaluaciones formativas como el NWEA MAP. El SAT ha pasado recientemente a un formato adaptativo de varias etapas.
Cómo implementar las pruebas adaptativas computarizadas
Nuestra revolucionaria plataforma, FastTest, facilita la publicación de un CAT. Una vez que cargue los textos de sus artículos y los parámetros IRT, puede elegir las opciones que desee para los pasos 2, 3 y 4 del algoritmo, simplemente haciendo clic en los elementos en nuestra interfaz fácil de usar.
Contáctenos para registrarse para obtener una cuenta gratuita en nuestra plataforma PAC líder en la industria o para hablar con uno de nuestros psicometristas con doctorado.

Nathan Thompson earned his PhD in Psychometrics from the University of Minnesota, with a focus on computerized adaptive testing. His undergraduate degree was from Luther College with a triple major of Mathematics, Psychology, and Latin. He is primarily interested in the use of AI and software automation to augment and replace the work done by psychometricians, which has provided extensive experience in software design and programming. Dr. Thompson has published over 100 journal articles and conference presentations, but his favorite remains https://scholarworks.umass.edu/pare/vol16/iss1/1/ .