
What is Automated Essay Scoring?
Automated essay scoring (AES) is an important application of machine learning and artificial intelligence to the field of psychometrics and assessment. In fact, it’s been around far longer than “machine learning” and “artificial intelligence” have been buzzwords in the general public! The field of psychometrics has been doing such groundbreaking work for decades.
So how does AES work, and how can you apply it?
What is automated essay scoring?
The first and most critical thing to know is that there is not an algorithm that “reads” the student essays. Instead, you need to train an algorithm. That is, if you are a teacher and don’t want to grade your essays, you can’t just throw them in an essay scoring system. You have to actually grade the essays (or at least a large sample of them) and then use that data to fit a machine learning algorithm. Data scientists use the term train the model, which sounds complicated, but if you have ever done simple linear regression, you have experience with training models.
There are three steps for automated essay scoring:
- Establish your data set. Begin by gathering a substantial collection of student essays, ensuring a diverse range of topics and writing styles. Each essay should be meticulously graded by human experts to create a reliable and accurate benchmark. This data set forms the foundation of your automated scoring system, providing the necessary examples for the machine learning model to learn from.
- Determine the features. Identify the key features that will serve as predictor variables in your model. These features might include grammar, syntax, vocabulary usage, coherence, structure, and argument strength. Carefully selecting these attributes is crucial as they directly impact the model’s ability to assess essays accurately. The goal is to choose features that are indicative of overall writing quality and are relevant to the scoring criteria.
- Train the machine learning model. Use the established data set and selected features to train your machine learning model. This involves feeding the graded essays into the model, allowing it to learn the relationship between the features and the assigned grades. Through iterative training and validation processes, the model adjusts its algorithms to improve accuracy. Continuous refinement and testing ensure that the model can reliably score new, unseen essays with a high degree of precision.
Here’s an extremely oversimplified example:
- You have a set of 100 student essays, which you have scored on a scale of 0 to 5 points.
- The essay is on Napoleon Bonaparte, and you want students to know certain facts, so you want to give them “credit” in the model if they use words like: Corsica, Consul, Josephine, Emperor, Waterloo, Austerlitz, St. Helena. You might also add other Features such as Word Count, number of grammar errors, number of spelling errors, etc.
- You create a map of which students used each of these words, as 0/1 indicator variables. You can then fit a multiple regression with 7 predictor variables (did they use each of the 7 words) and the 5 point scale as your criterion variable. You can then use this model to predict each student’s score from just their essay text.
Obviously, this example is too simple to be of use, but the same general idea is done with massive, complex studies. The establishment of the core features (predictive variables) can be much more complex, and models are going to be much more complex than multiple regression (neural networks, random forests, support vector machines).
Here’s an example of the very start of a data matrix for features, from an actual student essay. Imagine that you also have data on the final scores, 0 to 5 points. You can see how this is then a regression situation.
| Examinee | Word Count | i_have | best_jump | move | and_that | the_kids | well |
| 1 | 307 | 0 | 1 | 2 | 0 | 0 | 1 |
| 2 | 164 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 348 | 1 | 0 | 1 | 0 | 0 | 0 |
| 4 | 371 | 0 | 1 | 1 | 0 | 0 | 0 |
| 5 | 446 | 0 | 0 | 0 | 0 | 0 | 2 |
| 6 | 364 | 1 | 0 | 0 | 0 | 1 | 1 |
How do you score the essay?
If they are on paper, then automated essay scoring won’t work unless you have an extremely good software for character recognition that converts it to a digital database of text. Most likely, you have delivered the exam as an online assessment and already have the database. If so, your platform should include functionality to manage the scoring process, including multiple custom rubrics. An example of our FastTest platform is provided below.
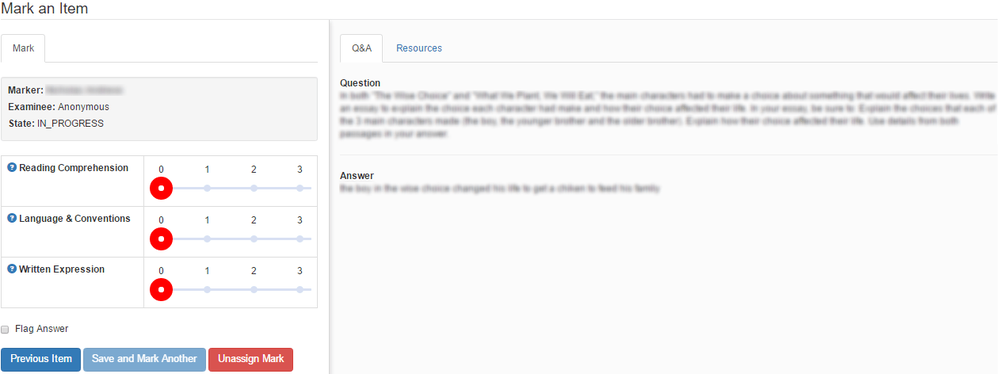
Some rubrics you might use:
- Grammar
- Spelling
- Content
- Style
- Supporting arguments
- Organization
- Vocabulary / word choice
How do you pick the Features?
This is one of the key research problems. In some cases, it might be something similar to the Napoleon example. Suppose you had a complex item on Accounting, where examinees review reports and spreadsheets and need to summarize a few key points. You might pull out a few key terms as features (mortgage amortization) or numbers (2.375%) and consider them to be Features. I saw a presentation at Innovations In Testing 2022 that did exactly this. Think of them as where you are giving the students “points” for using those keywords, though because you are using complex machine learning models, it is not simply giving them a single unit point. It’s contributing towards a regression-like model with a positive slope.
In other cases, you might not know. Maybe it is an item on an English test being delivered to English language learners, and you ask them to write about what country they want to visit someday. You have no idea what they will write about. But what you can do is tell the algorithm to find the words or terms that are used most often, and try to predict the scores with that. Maybe words like “jetlag” or “edification” show up in students that tend to get high scores, while words like “clubbing” or “someday” tend to be used by students with lower scores. The AI might also pick up on spelling errors. I worked as an essay scorer in grad school, and I can’t tell you how many times I saw kids use “ludacris” (name of an American rap artist) instead of “ludicrous” when trying to describe an argument. They had literally never seen the word used or spelled correctly. Maybe the AI model finds to give that a negative weight. That’s the next section!
How do you train a model?

Well, if you are familiar with data science, you know there are TONS of models, and many of them have a bunch of parameterization options. This is where more research is required. What model works the best on your particular essay, and doesn’t take 5 days to run on your data set? That’s for you to figure out. There is a trade-off between simplicity and accuracy. Complex models might be accurate but take days to run. A simpler model might take 2 hours but with a 5% drop in accuracy. It’s up to you to evaluate.
If you have experience with Python and R, you know that there are many packages which provide this analysis out of the box – it is a matter of selecting a model that works.
How effective is automated essay scoring?
Well, as psychometricians love to say, “it depends.” You need to do the model fitting research for each prompt and rubric. It will work better for some than others. The general consensus in research is that AES algorithms work as well as a second human, and therefore serve very well in that role. But you shouldn’t use them as the only score; of course, that’s impossible in many cases.
Here’s a graph from some research we did on our algorithm, showing the correlation of human to AES. The three lines are for the proportion of sample used in the training set; we saw decent results from only 10% in this case! Some of the models correlated above 0.80 with humans, even though this is a small data set. We found that the Cubist model took a fraction of the time needed by complex models like Neural Net or Random Forest; in this case it might be sufficiently powerful.

How can I implement automated essay scoring without writing code from scratch?
There are several products on the market. Some are standalone, some are integrated with a human-based essay scoring platform. ASC’s platform for automated essay scoring is SmartMarq; click here to learn more. It is currently in a standalone approach like you see below, making it extremely easy to use. It is also in the process of being integrated into our online assessment platform, alongside human scoring, to provide an efficient and easy way of obtaining a second or third rater for QA purposes.
Want to learn more? Contact us to request a demonstration.

Nathan Thompson, PhD
Latest posts by Nathan Thompson, PhD (see all)
- Psychometrics: Data Science for Assessment - June 5, 2024
- Setting a Cutscore to Item Response Theory - June 2, 2024
- What are technology enhanced items? - May 31, 2024