
Bellezza & Bellezza (1989): Error Similarity Analysis
This index evaluates error similarity analysis (ESA), namely estimating the probability that a given pair of examinees would have the same exact errors in common (EEIC), given the total number of errors they have in common (EIC) and the aggregated probability P of selecting the same distractor. Bellezza and Bellezza utilize the notation of k=EEIC and N=EIC, and calculate the probability

Note that this is summed from k to N; the example in the original article is that a pair of examinees had N=20 and k=18, so the equation above is calculated three times (k=18, 19, 20) to estimate the probability of having 18 or more EEIC out of 20 EIC. For readers of the Cizek (1999) book, note that N and k are presented correctly in the equation but their definitions in the text are transposed.
The calculation of P is left to the researcher to some extent. Published resources on the topic note that if examinees always selected randomly amongst distractors, the probability of an examinee selecting a given distractor is 1/d, where d is the number of incorrect answers, usually one less than the total number of possible responses. Two examinees randomly selecting the same distractor would be (1/d)(1/d). Summing across d distractors by multiplying by d, the calculation of P would be
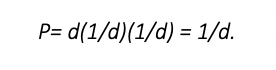
That is, for a four-option multiple choice item, d=3 and P=0.3333. For a five-option item, d=4 and P=0.25.
However, examinees most certainly do not select randomly amongst distractors. Suppose a four-option multiple-choice item was answered correctly by 50% (0.50) of the sample. The first distractor might be chosen by 0.30 of the sample, the second by 0.15, and the third by 0.05. SIFT calculates these probabilities and uses the observed values to provide a more realistic estimate of P.
SIFT therefore calculates this error similarity analysis index using the observed probabilities and also the random-selection assumption method, labeling them as B&B Obs and B&B Ran, respectively. The indices are calculated all possible pairs of examinees or all pairs in the same location, depending on the option selected in SIFT.
How to interpret this index? It is estimating a probability, so a smaller number means that the event can be expected to be very rare under the assumption of no collusion (that is, independent test taking). So a very small number is flagged as possible collusion. SIFT defaults to 0.001. As mentioned earlier, implementation of a Bonferroni correction might be prudent.
The software program Scrutiny! also calculates this ESA index. However, it utilizes a normal approximation rather than exact calculations, and details are not given regarding the calculation of P, so its results will not agree exactly with SIFT.
Cizek (1999) notes:
“Scrutiny! uses an approach to identifying copying called “error similarity analysis” or ESA—a method which, unfortunately, has not received strong recommendation in the professional literature. One review (Frary, 1993) concluded that the ESA method: 1) fails to utilize information from correct response similarity; 2) fails to consider total test performance of examinees; and 3) does not take into account the attractiveness of wrong options selected in common. Bay (1994) and Chason (1997) found that ESA was the least effective index for detecting copying of the three methods they compared.”
Want to implement this statistic? Download the SIFT software for free.
Nathan Thompson, PhD
Latest posts by Nathan Thompson, PhD (see all)
- Psychometrics: Data Science for Assessment - June 5, 2024
- Setting a Cutscore to Item Response Theory - June 2, 2024
- What are technology enhanced items? - May 31, 2024