Adaptive testing
AI in Teaching & Learning 2025: Personalized Learning, Smarter Tests, Stronger Guardrails
Why “AI in Education” Matters in 2025 AI in education has moved from experimentation to daily application. Whether you’re a school administrator, instructional designer, or classroom teacher, artificial intelligence offers three transformative benefits: time-saving automation,
Computerized Classification Testing: SPRT, GLRT, and Abraham Wald
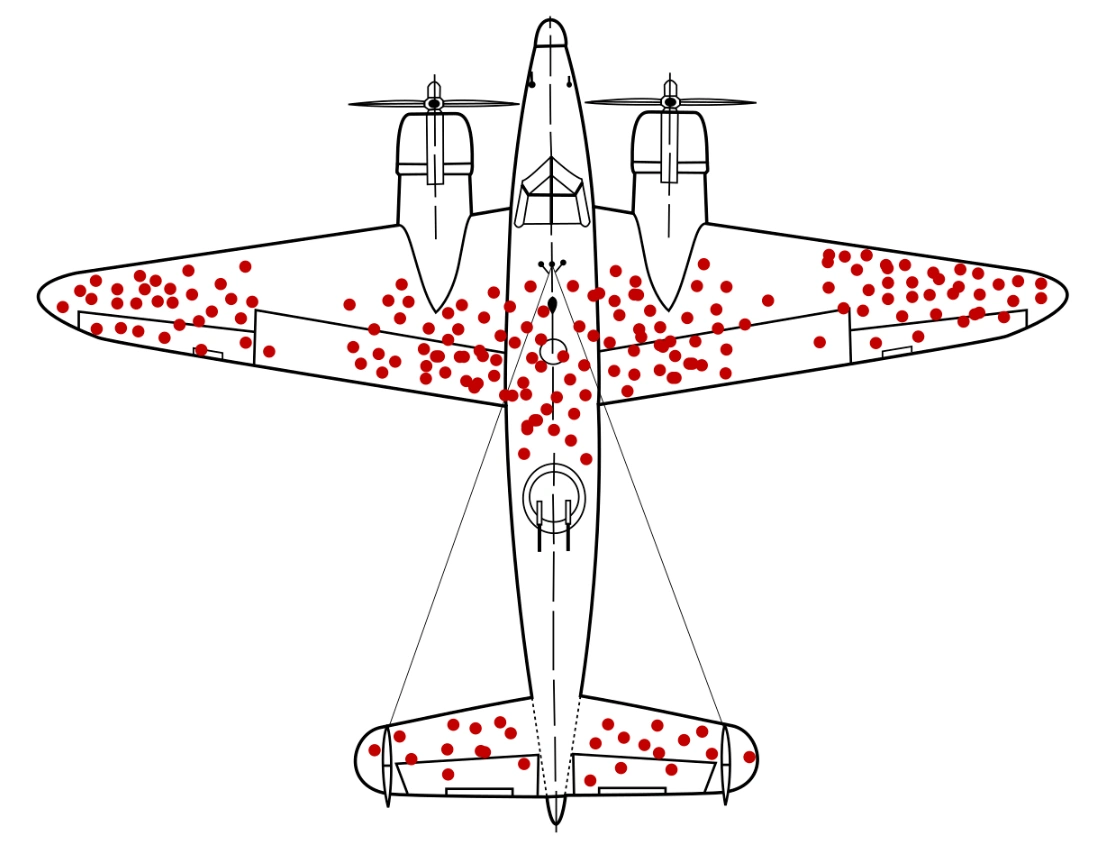
Computerized classification testing (CCT) refers to tests or assessments that are delivered to people, obviously via computer, for the purpose of classifying them into groups. Unlike traditional testing, which aims to estimate a student’s ability
Computerized Adaptive Testing (CAT): Introduction, Examples, Software
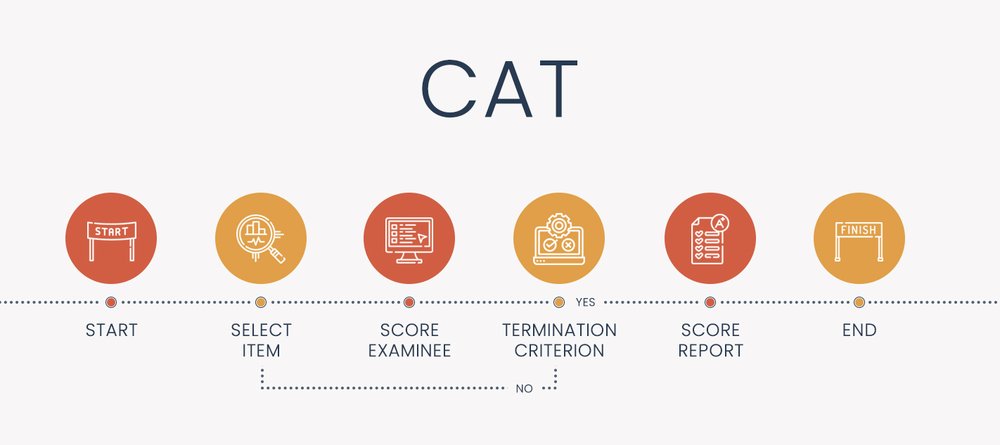
Computerized adaptive testing is an AI-based approach to assessment that dynamically personalizes the assessment based on your answers – making the test shorter, more accurate, more secure, more engaging, and fairer. If you do well,
Multistage Testing
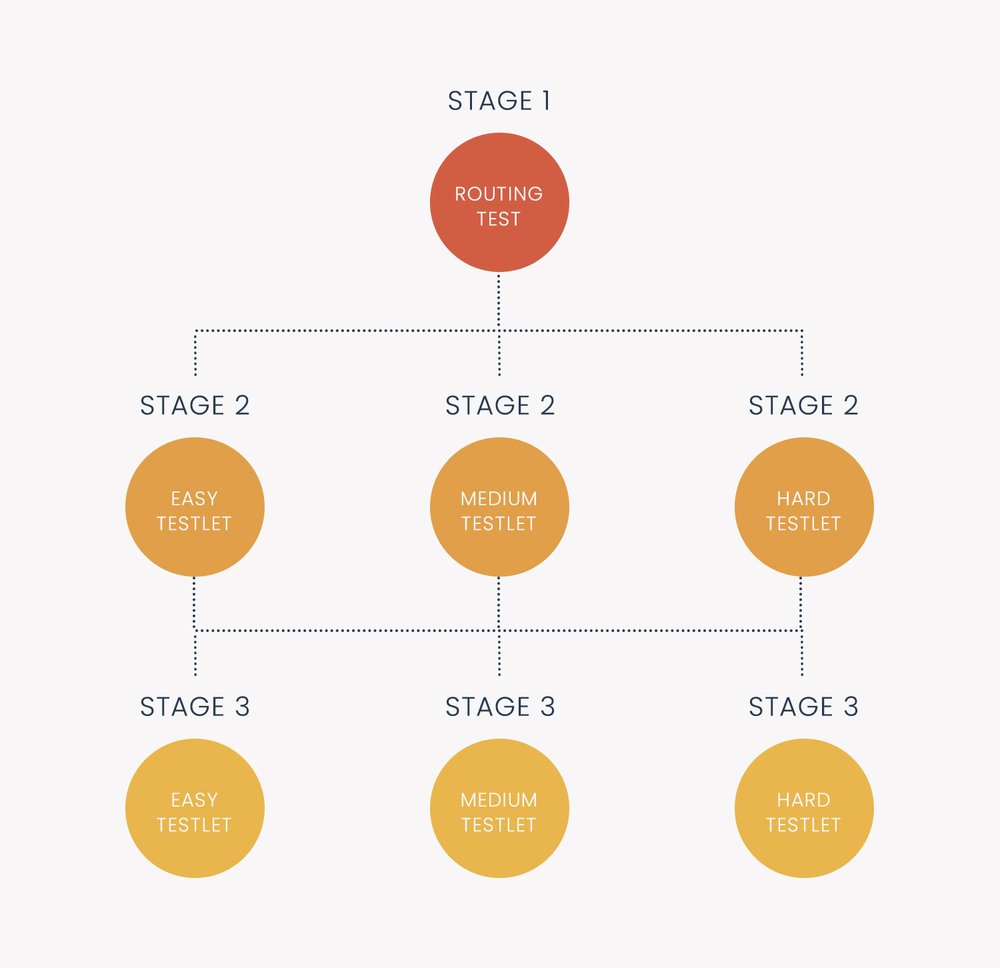
Multistage testing (MST) is a type of computerized adaptive testing (CAT). This means it is an exam delivered on computers which dynamically personalize it for each examinee or student. Typically, this is done with respect
Adaptive Testing SAT: Intro & Free Practice Test
The adaptive SAT (Scholastic Aptitude Test) exam was announced in January 2022 by the College Board, with the goal to modernize the test and make it more widely available, migrating the exam from paper-and-pencil to

Three Approaches for IRT Equating
IRT equating is the process of equating test forms or item pools using item response theory to ensure that scores are comparable no matter what set of items that an examinee sees. If you are

Paper-and-Pencil Testing: Still Around?
Paper-and-pencil testing used to be the only way to deliver assessments at scale. The introduction of computer-based testing (CBT) in the 1980s was a revelation – higher fidelity item types, immediate scoring & feedback, and

MICROCAT: What was assessment like in the 1980s?
ASC has been empowering organizations to develop better assessments since 1979. Curious as to how things were back then? Below is a copy of our newsletter from 1988, long before the days of sharing news

Monte Carlo simulation in adaptive testing
Simulation studies are an essential step in the development of a computerized adaptive test (CAT) that is defensible and meets the needs of your organization or other stakeholders. There are three types of simulations: Monte

What is the Sympson-Hetter Item Exposure Control?
Sympson-Hetter is a method of item exposure control within the algorithm of Computerized adaptive testing (CAT). It prevents the algorithm from over-using the best items in the pool. CAT is a powerful paradigm for delivering tests

Machine Learning in Psychometrics: Old News?
In the past decade, terms like machine learning, artificial intelligence, and data mining are becoming greater buzzwords as computing power, APIs, and the massively increased availability of data enable new technologies like self-driving cars. However, we’ve