Test Development
Test Timing in Computerized Adaptive Testing
In the realm of educational assessments and professional certifications, Computerized Adaptive Testing (CAT) has gained significant traction. This testing method, which is dynamic and efficient, adjusts the difficulty of questions based on a test-taker’s previous responses.

Test Administration: A Planning Guide
Test administration and other operations are a crucial part of the test development cycle, but often overlooked. Professional-grade exams such as certification or admissions are expensive to develop, so an organization wants to protect that

Is teaching to the test a bad thing?
One of the most cliche phrases associated with assessment is “teaching to the test.” I’ve always hated this phrase, because it is only used in a derogatory matter, almost always by people who do not

Oral Exams and Practical Assessments: Three Essentials for Remote Delivery
Oral exams, performance tests, and practical assessments are important components of many credentials or educational programs. Over the past 12 years, I have had the privilege of guiding credentialing organizations through the complex shift from

The Three Standard Errors: Mean, Measurement, Estimate
One of my graduate school mentors once said in class that there are three standard errors that everyone in the assessment or I/O Psychology field needs to know: the standard error of the mean, the

Digital Literacy Assessment and its Role in Modern Education
Digital literacy assessments are a critical aspect of modern educational and workforce development initiatives, given today’s fast-paced and technology-driven world, where digital literacy is essential in one’s education, occupation, and even in daily life. Defined

Summative vs Formative Assessment in Education
Summative and formative assessment are a crucial component of the educational process. If you work in the educational assessment field or even in educational generally, you have probably encountered these terms. What do they mean?
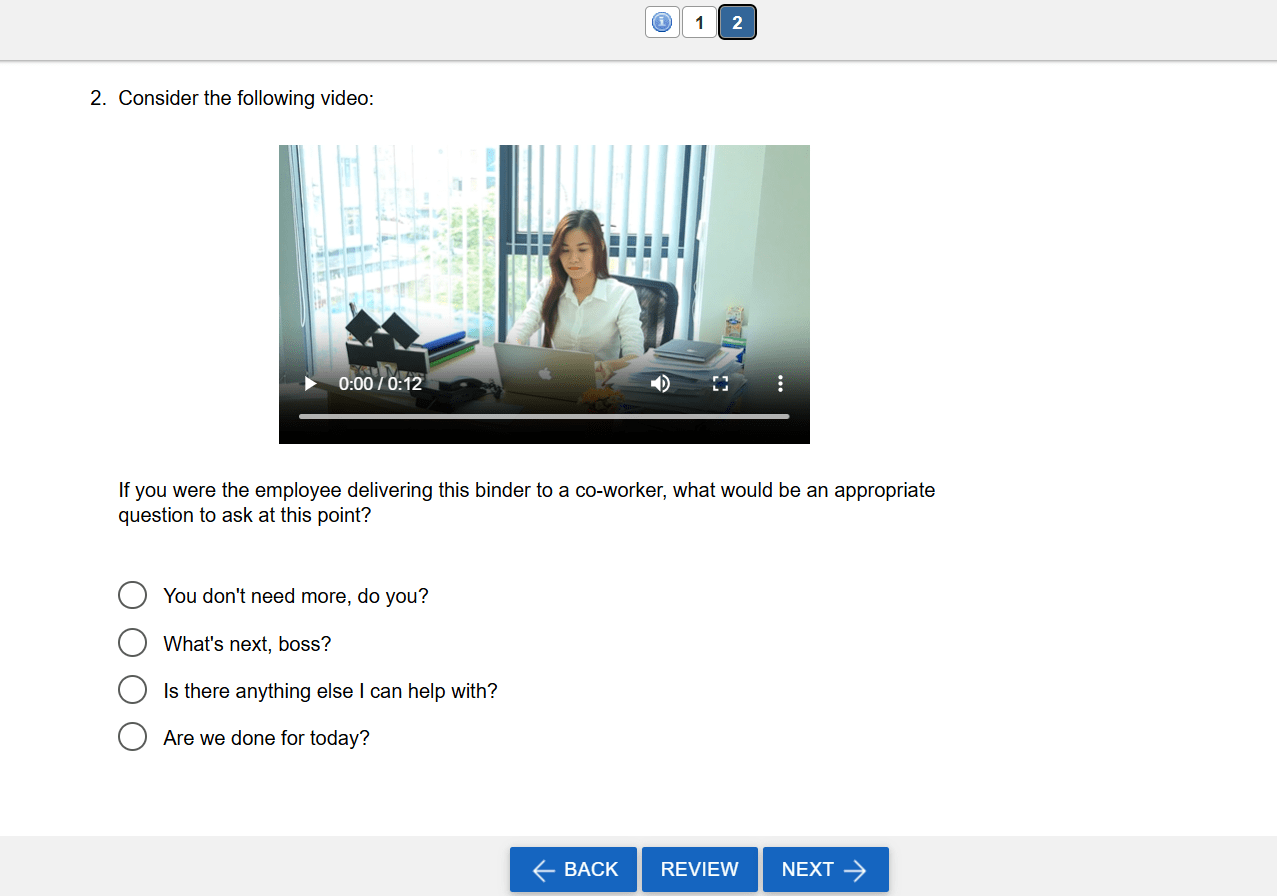
Situational Judgment Tests: Higher Fidelity in Pre-Employment Testing
Situational judgment tests (SJTs) are a type of assessment typically used in a pre-employment context to assess candidates’ soft skills and decision-making abilities. As the name suggests, we are not trying to assess something like
What is a z-score in assessment?
A z-score for an assessment is a normative score that measures the distance between a single person’s raw score and a raw score mean in standard deviation units. It conveys the location of the person

Confidence Intervals in Assessment and Psychometrics
Confidence intervals (CIs) are a fundamental concept in statistics, used extensively in assessment and measurement to estimate the reliability and precision of data. Whether in scientific research, business analytics, or health studies, confidence intervals provide

General Intelligence and Its Role in Assessment and Measurement
General intelligence, often symbolized as “g,” is a concept that has been central to psychology and cognitive science since the early 20th century. First introduced by Charles Spearman, general intelligence is a construct of an

Speeded Test vs Power Test
The concept of Speeded vs Power Test is one of the ways of differentiating psychometric or educational assessments. In the context of educational measurement and depending on the assessment goals and time constraints, tests are

Certification vs. Licensure Exams: Differences and Examples
Certification and Licensure exams are both types of professional workforce credentials, but a Certification is typically voluntary (usually a nonprofit) and Licensure is legally required (usually a government). However, Licensure is broader than workforce skills

Factor Analysis: Evaluating Dimensionality in Assessment
Factor analysis is a statistical technique widely used in research to understand and evaluate the underlying structure of assessment data. In fields such as education, psychology, and medicine, this approach to unsupervised machine learning helps
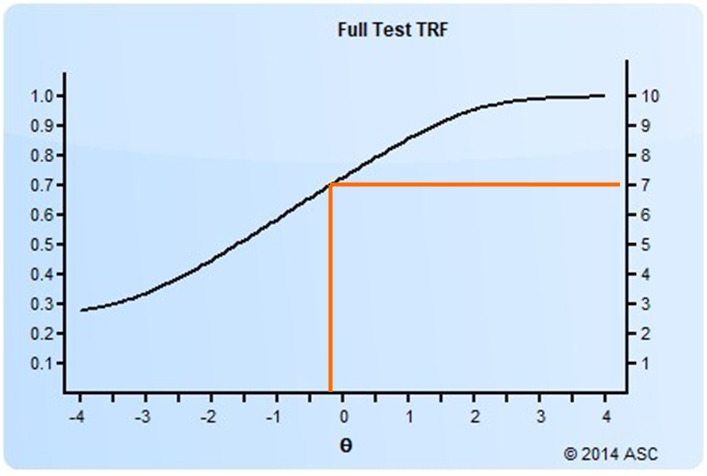
Setting a Cutscore to Item Response Theory
Setting a cutscore on a test scored with item response theory (IRT) requires some psychometric knowledge. This post will get you started. How do I set a cutscore with item response theory? There are two
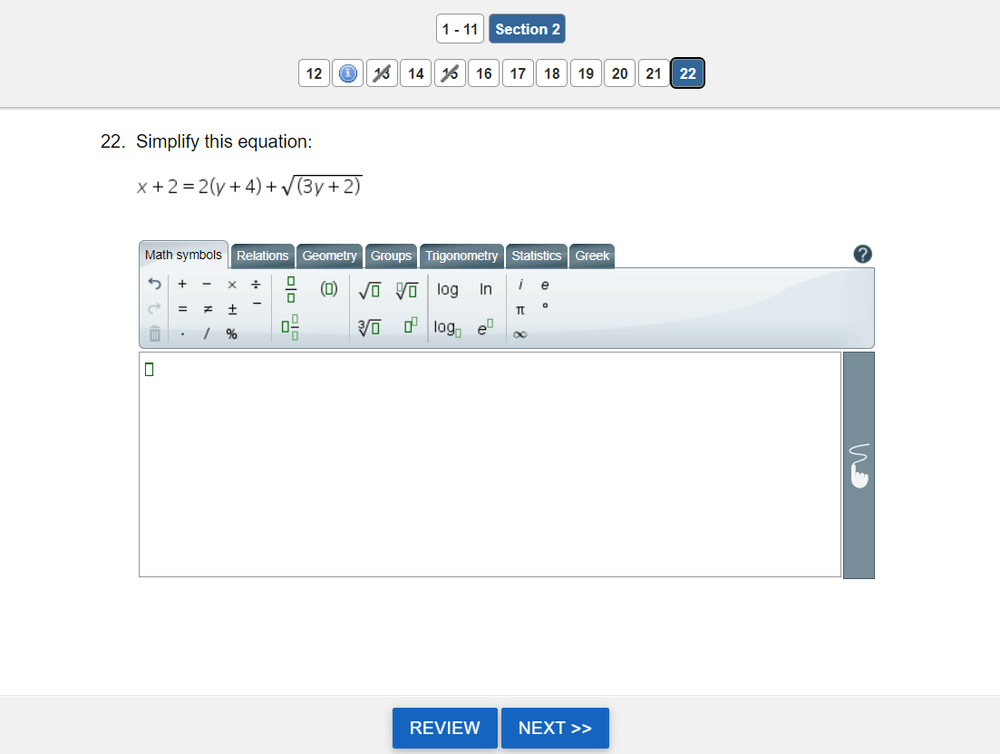
What are technology enhanced items?
Technology enhanced items are assessment items (questions) that utilize technology to improve the interaction of a test question in digital assessment, over and above what is possible with paper. Tech-enhanced items can improve examinee engagement
Modified-Angoff Method: Guide to a Defensible Cutscore
The modified-Angoff method is one of the most common ways to set a defensible cutscore on an exam, especially in Certification. A panel of experts reviews the items on a test and sets the cutscore based
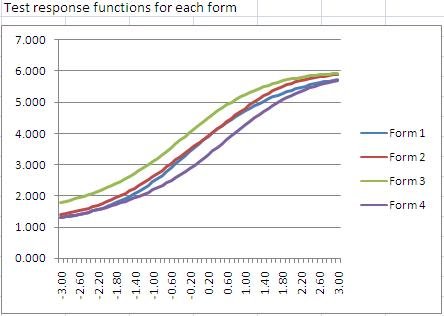
Item Response Theory (IRT): Intro, Models, and Examples
Item response theory (IRT) is a family of machine learning models in the field of psychometrics, which are used to design, analyze, validate, and score assessments. It is a very powerful psychometric paradigm that revolutionized