
The Bookmark Method of Standard Setting
The Bookmark Method of standard setting (Lewis, Mitzel, & Green, 1996) is a scientifically-based approach to setting cutscores on an examination. It allows stakeholders of an assessment to make decisions and classifications about examinees that are constructive rather than arbitrary (e.g., 70%), meet the goals of the test, and contribute to overall validity. A major advantage of the bookmark method over others is that it utilizes difficulty statistics on all items, making it very data-driven; but this can also be a disadvantage in situations where such data is not available. It also has the advantage of panelist confidence (Karantonis & Sireci, 2006).
The bookmark method operates by delivering a test to a representative sample (or population) of examinees, and then calculating the difficulty statistics for each item. We line up the items in order of difficulty, and experts review the items to place a bookmark where they think a cutscore should be. Nowadays, we use computer screens, but of course in the past this was often done by printing the items in paper booklets, and the experts would literally insert a bookmark.
What is standard setting?
Standard setting (Cizek & Bunch, 2006) is an integral part of the test development process even though it has been undervalued outside of practitioners’ view in the past (Bejar, 2008). Standard setting is the methodology of defining achievement or proficiency levels and corresponding cutscores. A cutscore is a score that serves as a measure of classifying test takers into categories.
Educational assessments and credentialing examinations are often employed to distribute test takers among ordered categories according to their performance across specific content and skills (AERA, APA, & NCME, 2014; Hambleton, 2013). For instance, in tests used for certification and licensing purposes, test takers are typically classified as “pass”—those who score at or above the cutscore—and those who “fail”. In education, students are often classified in terms of proficiency; the Nation’s Report Card assessment (NAEP) in the United States classifies students as Below Basic, Basic, Proficient, Advanced.
However, assessment results could come into question unless the cutscores are appropriately defined. This is why arbitrary cutscores are considered indefensible and lacking validity. Instead, psychometricians help test sponsors to set cutscores using methodologies from the scientific literature, driven by evaluations of item and test difficulty as well as examinee performance.
When to use the bookmark method?
Two approaches are mainly used in international practice to establish assessment standards: the Angoff method (Cizek, 2006) and the Bookmark method (Buckendahl, Smith, Impara, & Plake, 2000). The Bookmark method, unlike the Angoff method, requires the test to be administered prior to defining cutscores based on test data. This provides additional weight to the validity of the process, and better informs the subject matter experts during the process. Of course, many exams require a cutscore to be set before it is published, which is impossible with the bookmark; the Angoff procedure is very useful then.
How do I implement the bookmark method?
The process of standard setting employing the Bookmark method consists of the following stages:
- Identify a team of subject matter experts (SMEs); their number should be around 6-12, and led by a test developer/psychometrician/statistician
- Analyze test takers’ responses by means of the item response theory (IRT)
- Create a list items according to item difficulty in an ascending order
- Define the competency levels for test takers; for example, have the 6-12 experts discuss what should differentiate a “pass” candidate from a “fail” candidate
- Experts read the items in the ascending order (they do not need to see the IRT values), and place a bookmark where appropriate based on professional judgement across well-defined levels
- Calculate thresholds based on the bookmarks set, across all experts
- If needed, discuss results and perform a second round
Example of the Bookmark Method
If there are four competency levels such as the NAEP example, then SMEs need to set up three bookmarks in-between: first bookmark is set after the last item in a row that fits the minimally competent candidate for the first level, then second and third. There are thresholds/cutscores from 1 to 2, 2 to 3, and 3 to 4. SMEs perform this individually without discussion, by reading the items.
When all SMEs have provided their opinion, the standard setting coordinator combines all results into one spreadsheet and leads the discussion when all participants express their opinion referring to the bookmarks set. This might look like the sheet below. Note that SME4 had a relatively high standard in their mind, while SME2 had a low standard in their mind – placing virtually every student above an IRT score of 0.0 into the top category!
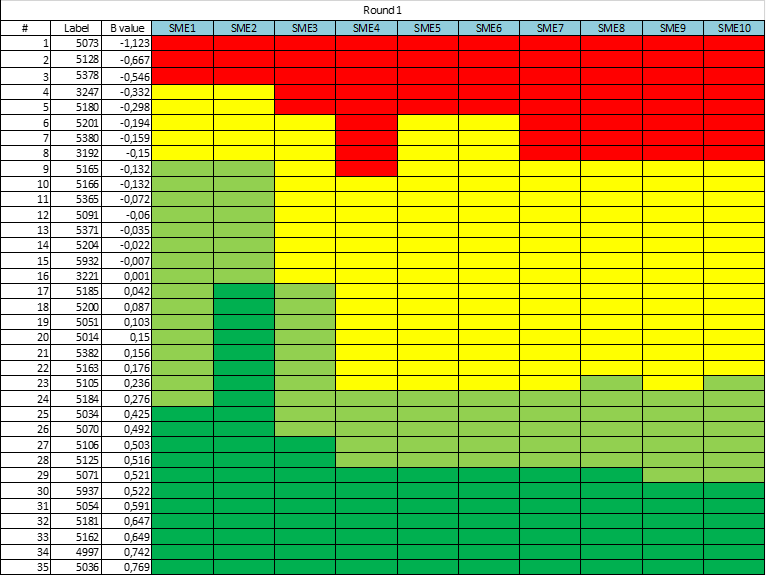
After the discussion, the SMEs are given one more opportunity to set the bookmarks again. Usually, after the exchange of opinions, the picture alters. SMEs gain consensus, and the variation in the graphic is reduced. An example of this is below.
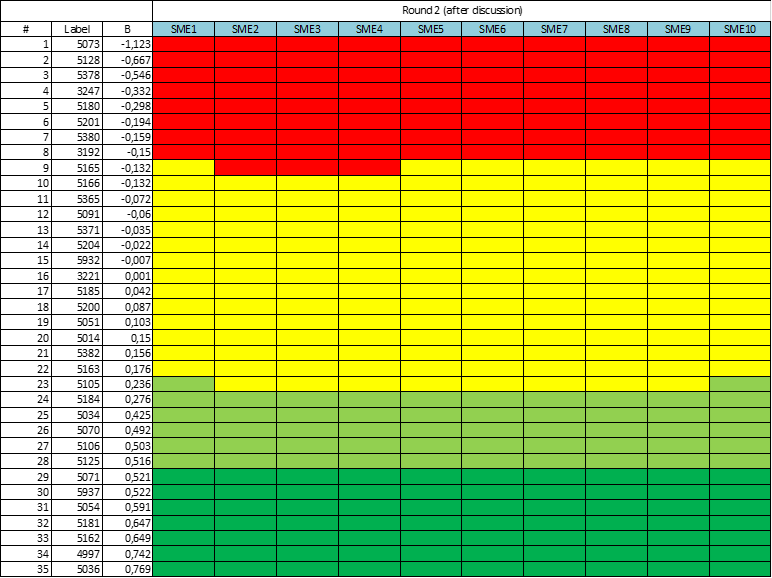
What to do with the results?
Based on the SMEs’ voting results, the coordinator or psychometrician calculates the final thresholds on the IRT scale, and provides them to the analytical team who would ultimately prepare reports for the assessment across competency levels. This might entail score reports to examinees, feedback reports to teachers, and aggregate reports to test sponsors, government officials, and more.
You can see how the scientific approach will directly impact the interpretations of such reports. Rather than government officials just knowing how many students scored 80-90% correct vs 90-100% correct, the results are framed in terms of how many students are truly proficient in the topic. This makes decisions from test scores – both at the individual and aggregate levels – much more defensible and informative. They become truly criterion-referenced. This is especially true when the scores are equated across years to account for differences in examinee distributions and test difficulty, and the standard can be demonstrated to be stable. For high-stakes examinations such as medical certification/licensure, admissions exams, and many more situations, this is absolutely critical.
Want to talk to an expert about implementing this for your exams? Contact us.
References
[AERA, APA, & NCME] (American Educational Research Association, American Psychological Association, & National Council on Measurement in Education). (2014). Standards for educational and psychological testing. Washington, DC: American Educational Research Association.
Bejar, I. I. (2008). Standard setting: What is it? Why is it important. R&D Connections, 7, 1-6. Retrieved from https://www.ets.org/Media/Research/pdf/RD_Connections7.pdf
Buckendahl, C. W., Smith, R. W., Impara, J. C., & Plake, B. S. (2000). A comparison of Angoff and Bookmark standard setting methods. Paper presented at the Annual Meeting of the Mid-Western Educational Research Association, Chicago, IL: October 25-28, 2000.
Cizek, G., & Bunch, M. (2006). Standard Setting: A Guide to Establishing and Evaluating Performance Standards on Tests. Thousand Oaks, CA: Sage.
Cizek, G. J. (2007). Standard setting. In Steven M. Downing and Thomas M. Haladyna (Eds.) Handbook of test development. Mahwah, NJ: Lawrence Erlbaum Associates, Publishers, pp. 225-258.
Hambleton, R. K. (2013). Setting performance standards on educational assessments and criteria for evaluating the process. In Setting performance standards, pp. 103-130. Routledge. Retrieved from https://www.nciea.org/publications/SetStandards_Hambleton99.pdf
Karantonis, A., & Sireci, S. (2006). The Bookmark Standard‐Setting Method: A Literature Review. Educational Measurement Issues and Practice 25(1):4 – 12.
Lewis, D. M., Mitzel, H. C., & Green, D. R. (1996, June). Standard setting: A Book-mark approach. In D. R. Green (Chair),IRT-based standard setting procedures utilizing behavioral anchoring. Symposium conducted at the Council of Chief State School Officers National Conference on Large-Scale Assessment, Phoenix, AZ.
Laila Issayeva M.Sc.
Latest posts by Laila Issayeva M.Sc. (see all)
- What is Digital Assessment, aka e-Assessment? - May 18, 2024
- What is a z-score? - November 15, 2023
- Digital Badges - May 29, 2023