The Generalized Partial Credit Model (GPCM)
The generalized partial credit model (GPCM, Muraki 1992) is an item response theory (IRT) model designed to work with items that are partial credit. That is, instead of just right/wrong as possible, scoring an examinee can receive partial points for completing some aspects of the item correctly. For example, a typical multiple-choice item is scored as 0 points for incorrect and 1 point for correct. A GPCM item might consist of 3 aspects and be 0 points for incorrect, 3 points for fully correct, and 1 or 2 points if the examinee only completes 1 or 2 of the aspects, but not all three.
Examples of GPCM items
GPCM items, therefore contain multiple point levels starting at 0. There are several examples that are common in the world of educational assessment.
The first example, which nearly everyone is familiar with, is essay rubrics. A student might be instructed to write an essay on why extracurriculars are important in school, with at least 3 supporting points. Such an essay might be scored with the number of points presented (0,1,2,3) as well as on grammar (0=10 or more errors, 1= 3-9 errors, and 2 = 2 errors or less). Here’s a shorter example.
Another example is multiple response items. For example, a student might be presented with a list of 5 animals and be asked to identify which are Mammals. There are 2 correct answers, so the possible points are 0,1,2.
Note that this also includes their tech-enhanced equivalents, such as drag and drop; such items might be reconfigured to dragging the animal names into boxes, but that’s just window dressing to make the item look sexier.
The National Assessment of Educational Progress and many other K-12 assessments utilize the GPCM since they so often use item types like this.
Why use the generalized partial credit model?
Well, the first part of the answer is a more general question: why use polytomous items? Well, these items are generally regarded to be higher-fidelity and assess deeper thinking than multiple-choice items. They also provide much more information than multiple-choice items in an IRT paradigm.
The second part of the answer is the specific question: If we have polytomous items, why use the GPCM rather than other models?
There are two parts to that answer that refer to the name generalized partial credit model. First, partial credit models are appropriate for items where the scoring starts at 0, and different polytomous items could have very different performances. In contrast, Likert-style items are also polytomous (almost always), but start at 1, and apply the same psychological response process on every item. For example, a survey where statements are presented and examinees are to, “Rate each on a scale of 1 to 5.”
Second, the “generalized” part of the name means that it includes a discrimination parameter for evaluating the measurement quality of an item. This is similar to using the 2PL or 3PL for dichotomous items rather than using the Rasch model and assuming items are of equal discrimination. There is also a Rasch partial credit model that is equivalent and can be used alongside Rasch dichotomous items, but this post is just focusing on GPCM.
Definition of the Generalized Partial Credit Model
The equation below (Embretson & Reise, 2000) defines the generalized partial credit.
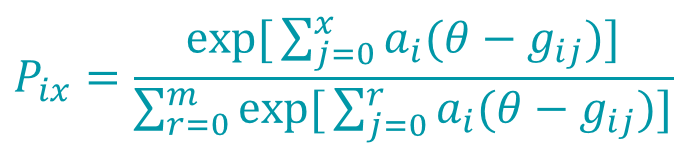
In this equation:
m – number of possible points
x – the student’s score on the item
i – index for item
θ – student ability
a – discrimination parameter for item i
gij – the boundary parameter for step j on item i; there are always m-1 boundaries
r – an index used to manage the summation.
What do these mean? The a parameter is the same concept as the a parameter in dichotomous IRT, where 0.5 might be low and 1.2 might be high. The boundary parameters define the steps or thresholds that explain how the GPCM works, which will become clearer when you see the graph below.
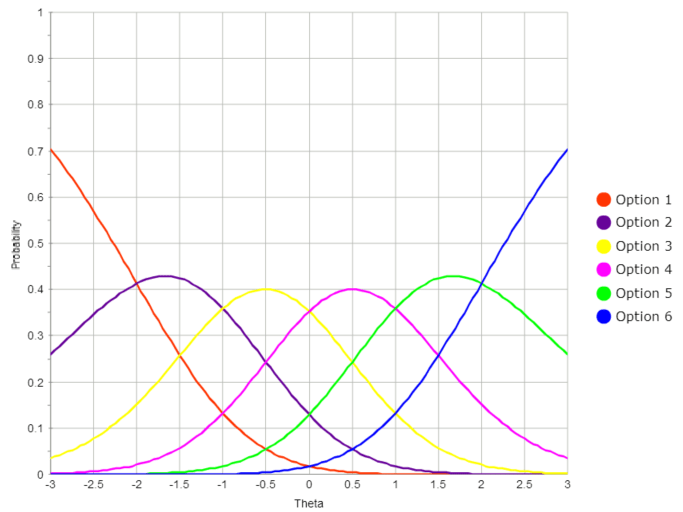
As an example, let us consider a 4-point item with the following parameters.

If you use those numbers to graph the functions for each point level as a function of theta, you would see a graph like the one below. Here, consider Option 1 to be the probability of getting 0 points; this is a very high probability for the lowest examinees but drops as ability increases.
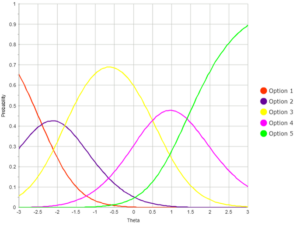
The Option 5 line is for receiving all possible points; high probability for the best examinees, but probability decreases as ability does. Between, we have probability curves for 1, 2, and 3 points. If an examinee has a theta of -0.5, they have a high probability of getting 2 points on the item (yellow curve).
The boundary parameters mentioned earlier have a very real interpretation with this graph; they are literally the boundaries between the curves. That is the theta level, at which 1 point (purple) becomes more likely that 0 points (red) are at -2.4 where the two lines cross. Note that this is the first boundary parameter b1 in the image earlier.
How to use the GPCM
As mentioned before, the GPCM is appropriate to use as your IRT model for multi-point items in an educational context, as opposed to Likert-style psychological items. They’re almost always used in conjunction with the 2PL or 3PL dichotomous models; consider a test of 25 multiple-choice items, 3 multiple response items, and an essay with 2 rubrics.
To implement, you need an IRT software program that can estimate dichotomous and polytomous items jointly, such as Xcalibre. Consider the screenshot below to specify these.

If you implement IRT with Xcalibre, it produces a page like this for each GPCM item.
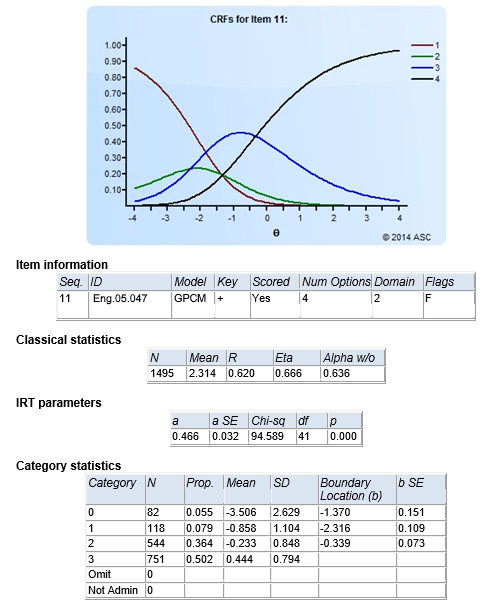
To score students with the GPCM, you either need to use the IRT program like Xcalibre to score students or a test delivery system that has been specifically designed to support the GPCM in the item banker and implement GPCM in scoring routines. The former only works when you are doing the IRT analysis after all examinees have completed a test; if you have a continuous deployment of assessments, you will need to use the latter approach.
Where can I learn more?
> <
IRT textbooks will provide a treatment of polytomous models like the generalized partial credit model. Examples are de Ayala (2010) and Embretson & Reise (2000). Also, I recommend the 2010 book by Nering and Ostini, which was previously available as a monograph.
Nathan Thompson, PhD
Latest posts by Nathan Thompson, PhD (see all)
- Psychometrics: Data Science for Assessment - June 5, 2024
- Setting a Cutscore to Item Response Theory - June 2, 2024
- What are technology enhanced items? - May 31, 2024