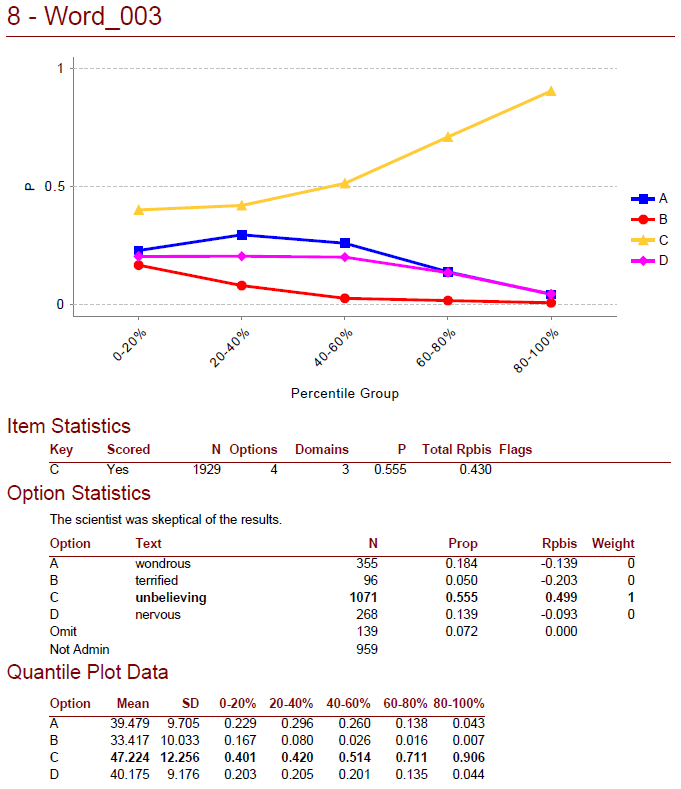
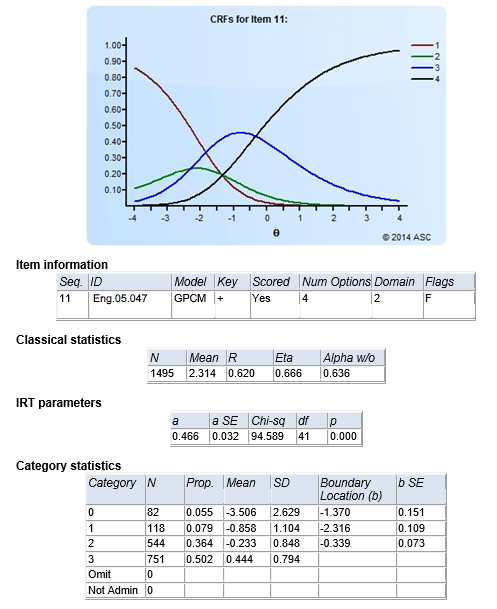
Classical Test Theory and Item Response Theory (CTT & IRT) are the two primary psychometric paradigms. That is, they are mathematical approaches to how tests are analyzed and scored. They differ quite substantially in substance and complexity, even though they both nominally do the same thing, which is statistically analyze test data to ensure reliability and validity. CTT is quite simple, easily understood, and works with small samples, but IRT is far more powerful and effective, so it is used by most big exams in the world.
So how are they different, and how can you effectively choose the right solution? First, let’s start by defining the two. This is just a brief intro; there are entire books dedicated to the details!
Classical Test Theory
CTT is an approach that is based on simple mathematics; primarily averages, proportions, and correlations. It is more than 100 years old, but is still used quite often, with good reason. In addition to working with small sample sizes, it is very simple and easy to understand, which makes it useful for working directly with content experts to evaluate, diagnose, and improve items or tests.
IRT is a much more complex approach to analyzing tests. Moreover, it is not just for analyzing; it is a complete psychometric paradigm that changes how item banks are developed, test forms are designed, tests are delivered (adaptive or linear-on-the-fly), and scores produced. There are many benefits to this approach that justify the complexity, and there is good reason that all major examinations in the world utilize IRT. Learn more about IRT here.
Similarities between Classical Test Theory and Item Response Theory
CTT & IRT are both foundational frameworks in psychometrics aimed at improving the reliability and validity of psychological assessments. Both methodologies involve item analysis to evaluate and refine test items, ensuring they effectively measure the intended constructs. Additionally, IRT and CTT emphasize the importance of test standardization and norm-referencing, which facilitate consistent administration and meaningful score interpretation. Despite differing in specific techniques both frameworks ultimately strive to produce accurate and consistent measurement tools. These shared goals highlight the complementary nature of IRT and CTT in advancing psychological testing.
Differences between Classical Test Theory and Item Response Theory
Test-Level and Subscore-Level Analysis
CTT statistics for total scores and subscores include coefficient alpha reliability, standard error of measurement (a function of reliability and SD), descriptive statistics (average, SD…), and roll-ups of item statistics (e.g., mean Rpbis).
With IRT, we utilize the same descriptive statistics, but the scores are now different (theta, not number-correct). The standard error of measurement is now a conditional function, not a single number. The entire concept of reliability is dropped, and replaced with the concept of precision, and also as that same conditional function.
IRT replaces the difficulty and discrimination with its own quantifications, called simply b and a. In addition, it can add a c parameter for guessing effects. More importantly, it creates entirely new classes of statistics for partial credit or rating scale items.
Scoring
CTT scores tests with traditional scoring: number-correct, proportion-correct, or sum-of-points. CTT interprets test scores based on the total number of correct responses, assuming all items contribute equally. IRT scores examinees directly on a latent scale, which psychometricians call theta, allowing for more nuanced and precise ability estimates.
Linking and Equating
Linking and equating is a statistical analysis to determine comparable scores on different forms; e.g., Form A is “two points easier” than Form B and therefore a 72 on Form A is comparable to a 70 on Form B. CTT has several methods for this, including the Tucker and Levine methods, but there are methodological issues with these approaches. These issues, and other issues with CTT, eventually led to the development of IRT in the 1960s and 1970s.
One major advantage of IRT, as a corollary to the strong linking/equating, is that we can link/equate not just across multiple forms in one grade, but from grade to grade. This produces a vertical scale. A vertical scale can span across multiple grades, making it much easier to track student growth, or to measure students that are off-grade in their performance (e.g., 7th grader that is at a 5th grade level). A vertical scale is a substantial investment, but is extremely powerful for K-12 assessments.
Sample Sizes
Classical test theory can work effectively with 50 examinees, and provide useful results with as little as 20. Depending on the IRT model you select (there are many), the minimum sample size can be 100 to 1,000.
Sample- and Test-Dependence
CTT analyses are sample-dependent and test-dependent, which means that such analyses are performed on a single test form and set of students. It is possible to combine data across multiple test forms to create a sparse matrix, but this has a detrimental effect on some of the statistics (especially alpha), even if the test is of high quality, and the results will not reflect reality.
For example, if Grade 7 Math has 3 forms (beginning, middle, end of year), it is conceivable to combine them into one “super-matrix” and analyze together. The same is true if there are 3 forms given at the same time, and each student randomly receives one of the forms. In that case, 2/3 of the matrix would be empty, which psychometricians call sparse.
Distractor Analysis
Classical test theory will analyze the distractors of a multiple choice item. IRT models, except for the rarely-used Nominal Response Model, do not. So even if you primarily use IRT, psychometricians will also use CTT for this.
Guessing
IRT has a parameter to account for guessing, though some psychometricians argue against its use. CTT has no effective way to account for guessing.
Adaptive Testing
There are rare cases where adaptive testing (personalized assessment) can be done with classical test theory. However, it pretty much requires the use of item response theory for one important reason: IRT puts people and items onto the same latent scale.
Linear Test Design
CTT and IRT differ in how test forms are designed and built. CTT works best when there are lots of items of middle difficulty, as this maximizes the coefficient alpha reliability. However, there are definitely situations where the purpose of the assessment is otherwise. IRT provides stronger methods for designing such tests, and then scoring as well.
So… How to Choose?
There is no single best answer to the question of CTT vs. IRT. You need to evaluate the aspects listed above, and in some cases other aspects (e.g., financial, or whether you have staff available with the expertise in the first place). In many cases, BOTH are necessary. This is especially true because IRT does not provide an effective and easy-to-understand distractor analysis that you can use to discuss with subject matter experts. It is for this reason that IRT software will typically produce CTT analysis too, though the reverse is not true.
IRT is very powerful, and can provide additional information about tests if used just for analyzing results to evaluate item and test performance. A researcher might choose IRT over CTT for its ability to provide detailed item-level data, handle varying item characteristics, and improve the precision of ability estimates. IRT’s flexibility and advanced modeling capabilities make it suitable for complex assessments and adaptive testing scenarios.
However, IRT is really only useful if you are going to make it your psychometric paradigm, thereby using it in the list of activities above, especially IRT scoring of examines. Otherwise, IRT analysis is merely just another way of looking test and item performance that will correlate substantially with CTT.
Nathan Thompson earned his PhD in Psychometrics from the University of Minnesota, with a focus on computerized adaptive testing. His undergraduate degree was from Luther College with a triple major of Mathematics, Psychology, and Latin. He is primarily interested in the use of AI and software automation to augment and replace the work done by psychometricians, which has provided extensive experience in software design and programming. Dr. Thompson has published over 100 journal articles and conference presentations, but his favorite remains https://scholarworks.umass.edu/pare/vol16/iss1/1/ .
Ready to talk to an assessment expert?
Get in touch, and we'll meet to discuss how we can improve your exam development, delivery, and psychometrics!