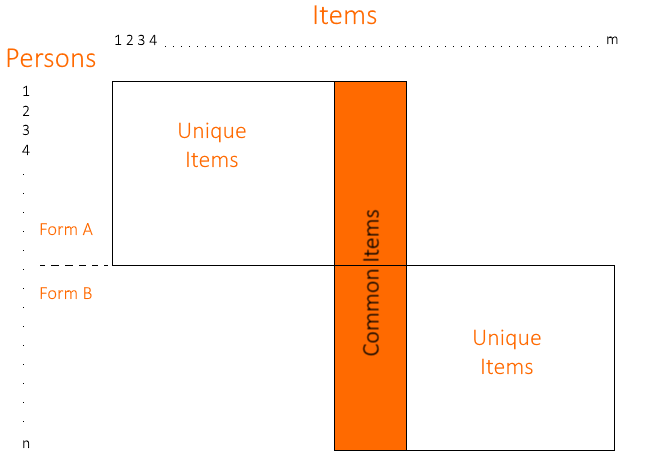
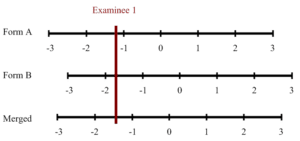
HR assessment is a critical part of the HR ecosystem, used to select the best candidates with pre-employment testing, assess training, certify skills, and more. But there is a huge range in quality, as well as a wide range in the type of assessment that it is designed for. This post will break down the different approaches and help you find the best solution.
HR assessment platforms help companies create effective assessments, thus saving valuable resources, improving candidate experience & quality, providing more accurate and actionable information about human capital, and reducing hiring bias. But, finding software solutions that can help you reap these benefits can be difficult, especially because of the explosion of solutions in the market. If you are lost on which tools will help you develop and deliver your own HR assessments, this guide is for you.
What is HR assessment?
HR assessment is a comprehensive process used by human resources professionals to evaluate various aspects of potential and current employees’ abilities, skills, and performance. This process encompasses a wide range of tools and methodologies designed to provide insights into an individual’s suitability for a role, their developmental needs, and their potential for future growth within the organization.

The primary goal of HR assessment is to make informed decisions about recruitment, employee development, and succession planning. During the recruitment phase, HR assessments help in identifying candidates who possess the necessary competencies and cultural fit for the organization.
There are various types of assessments used in HR. Here are four main areas, though this list is by no means exhaustive.
- Pre-employment tests to select candidates
- Post-training assessments
- Certificate or certification exams (can be internal or external)
- 360-degree assessments and other performance appraisals
Pre-employment tests
Finding good employees in an overcrowded market is a daunting task. In fact, according to the Harvard Business Review, 80% of employee turnover is attributed to poor hiring decisions. Bad hires are not only expensive, but can also adversely affect cultural dynamics in the workforce. This is one area where HR assessment software shows its value.
There are different types of pre-employment assessments. Each of them achieves a different goal in the hiring process. The major types of pre-employment assessments include:
Personality tests: Despite rapidly finding their way into HR, these types of pre-employment tests are widely misunderstood. Personality tests answer questions in the social spectrum. One of the main goals of these tests is to quantify the success of certain candidates based on behavioral traits.
Aptitude tests: Unlike personality tests or emotional intelligence tests which tend to lie on the social spectrum, aptitude tests measure problem-solving, critical thinking, and agility. These types of tests are popular because can predict job performance than any other type because they can tap into areas that cannot be found in resumes or job interviews.
Skills Testing: The kinds of tests can be considered a measure of job experience; ranging from high-end skills to low-end skills such as typing or Microsoft excel. Skill tests can either measure specific skills such as communication or measure generalized skills such as numeracy.
Emotional Intelligence tests: These kinds of assessments are a new concept but are becoming important in the HR industry. With strong Emotional Intelligence (EI) being associated with benefits such as improved workplace productivity and good leadership, many companies are investing heavily in developing these kinds of tests. Despite being able to be administered to any candidates, it is recommended they be set aside for people seeking leadership positions, or those expected to work in social contexts.
Risk tests: As the name suggests, these types of tests help companies reduce risks. Risk assessments offer assurance to employers that their workers will commit to established work ethics and not involve themselves in any activities that may cause harm to themselves or the organization. There are different types of risk tests. Safety tests, which are popular in contexts such as construction, measure the likelihood of the candidates engaging in activities that can cause them harm. Other common types of risk tests include Integrity tests.
Here’s a webinar that we hosted which talks in detail about types of pre-employment assessment, when to use them, how it fits into the big picture of recruitment, and much more.
Post-training assessments
This refers to assessments that are delivered after training. It might be a simple quiz after an eLearning module, up to a certification exam after months of training (see next section). Often, it is somewhere in between. For example you might take an afternoon sit through a training course, after which you take a formal test that is required to do something on the job. When I was a high school student, I worked in a lumber yard, and did exactly this to become an OSHA-approved forklift driver.
Certificate or certification exams
Sometimes, the exam process can be high-stakes and formal. It is then a certificate or certification, or sometimes a licensure exam. More on that here. This can be internal to the organization, or external.
Internal certification: The credential is awarded by the training organization, and the exam is specifically tied to a certain product or process that the organization provides in the market. There are many such examples in the software industry. You can get certifications in AWS, SalesForce, Microsoft, etc. One of our clients makes MRI and other medical imaging machines; candidates are certified on how to calibrate/fix them.
External certification: The credential is awarded by an external board or government agency, and the exam is industry-wide. An example of this is the SIE exams offered by FINRA. A candidate might go to work at an insurance company or other financial services company, who trains them and sponsors them to take the exam in hopes that the company will get a return by the candidate passing and then selling their insurance policies as an agent. But the company does not sponsor the exam; FINRA does.
360-degree assessments and other performance appraisals
Job performance is one of the most important concepts in HR, and also one that is often difficult to measure. John Campbell, one of my thesis advisors, was known for developing an 8-factor model of performance. Some aspects are subjective, and some are easily measured by real-world data, such as number of widgets made or number of cars sold by a car salesperson. Others involve survey-style assessments, such as asking customers, business partners, co-workers, supervisors, and subordinates to rate a person on a Likert scale. HR assessment platforms are needed to develop, deliver, and score such assessments.
The Benefits of Using Professional-Level Exam Software
Now that you have a good understanding of what pre-employment and other HR tests are, let’s discuss the benefits of integrating pre-employment assessment software into your hiring process. Here are some of the benefits:
Saves Valuable resources
Unlike the lengthy and costly traditional hiring processes, pre-employment assessment software helps companies increase their ROI by eliminating HR snugs such as face-to-face interactions or geographical restrictions. Pre-employment testing tools can also reduce the amount of time it takes to make good hires while reducing the risks of facing the financial consequences of a bad hire.
Supports Data-Driven Hiring Decisions
Data runs the modern world, and hiring is no different. You are better off letting complex algorithms crunch the numbers and help you decide which talent is a fit, as opposed to hiring based on a hunch or less-accurate methods like an unstructured interview. Pre-employment assessment software helps you analyze assessments and generate reports/visualizations to help you choose the right candidates from a large talent pool.
Improving candidate experience
Candidate experience is an important aspect of a company’s growth, especially considering the fact that 69% of candidates admitting not to apply for a job in a company after having a negative experience. Good candidate experience means you get access to the best talent in the world.
Elimination of Human Bias
Traditional hiring processes are based on instinct. They are not effective since it’s easy for candidates to provide false information on their resumes and cover letters. But, the use of pre-employment assessment software has helped in eliminating this hurdle. The tools have leveled the playing ground, and only the best candidates are considered for a position.
What To Consider When Choosing HR assessment tools
Now that you have a clear idea of what pre-employment tests are and the benefits of integrating pre-employment assessment software into your hiring process, let’s see how you can find the right tools.
Here are the most important things to consider when choosing the right pre-employment testing software for your organization.
Ease-of-use
The candidates should be your top priority when you are sourcing pre-employment assessment software. This is because the ease of use directly co-relates with good candidate experience. Good software should have simple navigation modules and easy comprehension.
Here is a checklist to help you decide if a pre-employment assessment software is easy to use:
- Are the results easy to interpret?
- What is the UI/UX like?
- What ways does it use to automate tasks such as applicant management?
- Does it have good documentation and an active community?
Tests Delivery and Remote Proctoring
Good online assessment software should feature good online proctoring functionalities. This is because most remote jobs accept applications from all over the world. It is therefore advisable to choose a pre-employment testing software that has secure remote proctoring capabilities. Here are some things you should look for on remote proctoring;
- Does the platform support security processes such as IP-based authentication, lockdown browser, and AI-flagging?
- What types of online proctoring does the software offer? Live real-time, AI review, or record and review?
- Does it let you bring your own proctor?
- Does it offer test analytics?
Test & data security, and compliance
Defensibility is what defines test security. There are several layers of security associated with pre-employment test security. When evaluating this aspect, you should consider what pre-employment testing software does to achieve the highest level of security. This is because data breaches are wildly expensive.
The first layer of security is the test itself. The software should support security technologies and frameworks such as lockdown browser, IP-flagging, and IP-based authentication.
The other layer of security is on the candidate’s side. As an employer, you will have access to the candidate’s private information. How can you ensure that your candidate’s data is secure? That is reason enough to evaluate the software’s data protection and compliance guidelines.
A good pre-employment testing software should be compliant with certifications such as GDRP. The software should also be flexible to adapt to compliance guidelines from different parts of the world.
Questions you need to ask;
- What mechanisms does the software employ to eliminate infidelity?
- Is their remote proctoring function reliable and secure?
- Are they compliant with security compliance guidelines including ISO, SSO, or GDPR?
- How does the software protect user data?
Psychometrics
Psychometrics is the science of assessment, helping to drive accurate scores from defensible tests, as well as making them more efficient, reducing bias, and a host of other benefits. You should ensure that your solution supports the necessary level of psychometrics. Some suggestions:
- Storing item statistics in the item banker
- Managing modified-Angoff studies
- Using test statistics for form assembly, such as the test information function
- Support for item response theory
- Adaptive testing
User experience
A good user experience is a must-have when you are sourcing any enterprise software. A new age pre-employment testing software should create user experience maps with both the candidates and employer in mind. Some ways you can tell if a software offers a seamless user experience includes;
- User-friendly interface
- Simple and easy to interact with
- Easy to create and manage item banks
- Clean dashboard with advanced analytics and visualizations
Customizing your user-experience maps to fit candidates’ expectations attracts high-quality talent.
Scalability and automation
With a single job post attracting approximately 250 candidates, scalability isn’t something you should overlook. A good pre-employment testing software should thus have the ability to handle any kind of workload, without sacrificing assessment quality.
It is also important you check the automation capabilities of the software. The hiring process has many repetitive tasks that can be automated with technologies such as Machine learning, Artificial Intelligence (AI), and robotic process automation (RPA).
Here are some questions you should consider in relation to scalability and automation;
- Does the software offer Automated Item Generation (AIG)?
- How many candidates can it handle?
- Can it support candidates from different locations worldwide?
Reporting and analytics
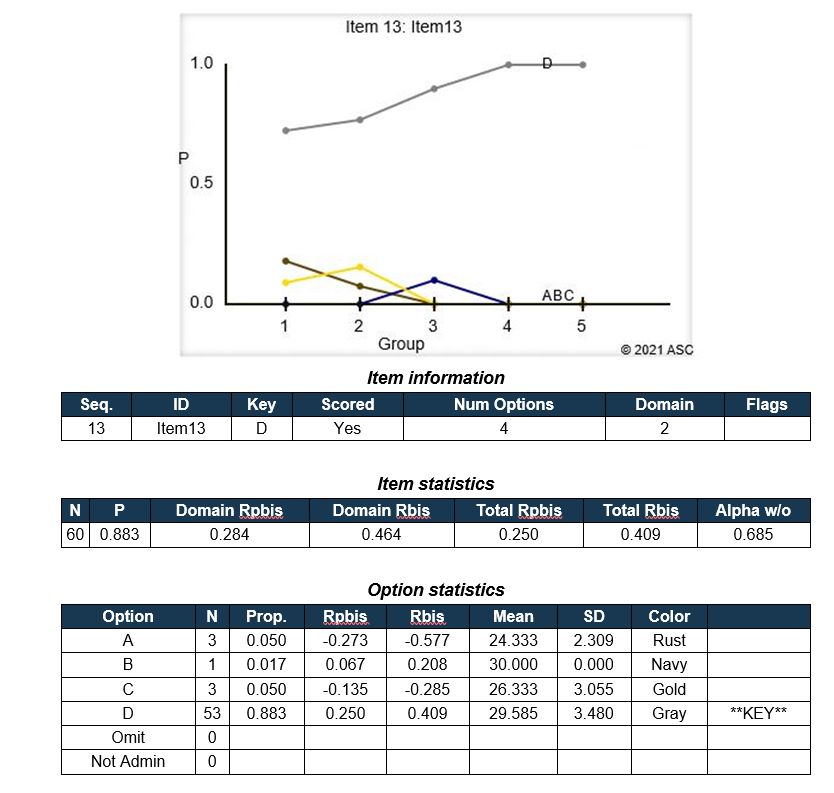
A good pre-employment assessment software will not leave you hanging after helping you develop and deliver the tests. It will enable you to derive important insight from the assessments.
The analytics reports can then be used to make data-driven decisions on which candidate is suitable and how to improve candidate experience. Here are some queries to make on reporting and analytics.
- Does the software have a good dashboard?
- What format are reports generated in?
- What are some key insights that prospects can gather from the analytics process?
- How good are the visualizations?
Customer and Technical Support
Customer and technical support is not something you should overlook. A good pre-employment assessment software should have an Omni-channel support system that is available 24/7. This is mainly because some situations need a fast response. Here are some of the questions your should ask when vetting customer and technical support:
- What channels of support does the software offer/How prompt is their support?
- How good is their FAQ/resources page?
- Do they offer multi-language support mediums?
- Do they have dedicated managers to help you get the best out of your tests?
Conclusion
Finding the right HR assessment software is a lengthy process, yet profitable in the long run. We hope the article sheds some light on the important aspects to look for when looking for such tools. Also, don’t forget to take a pragmatic approach when implementing such tools into your hiring process.
Are you stuck on how you can use pre-employment testing tools to improve your hiring process? Feel free to contact us and we will guide you on the entire process, from concept development to implementation. Whether you need off-the-shelf tests or a comprehensive platform to build your own exams, we can provide the guidance you need. We also offer free versions of our industry-leading software FastTest and Assess.ai – visit our Contact Us page to get started!
If you are interested in delving deeper into leadership assessments, you might want to check out this blog post. For more insights and an example of how HR assessments can fail, check out our blog post called Public Safety Hiring Practices and Litigation. The blog post titled Improving Employee Retention with Assessment: Strategies for Success explores how strategic use of assessments throughout the employee lifecycle can enhance retention, build stronger teams, and drive business success by aligning organizational goals with employee development and engagement.



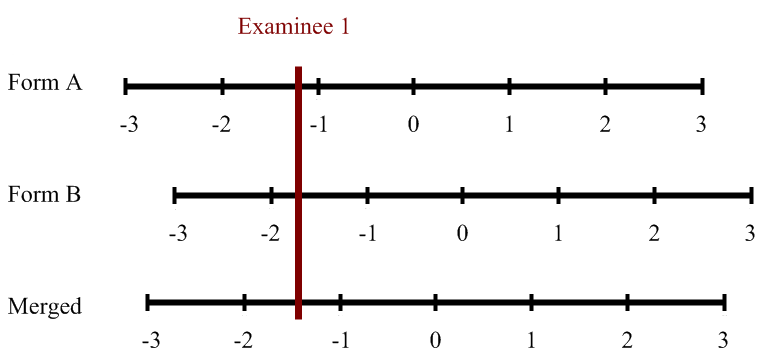
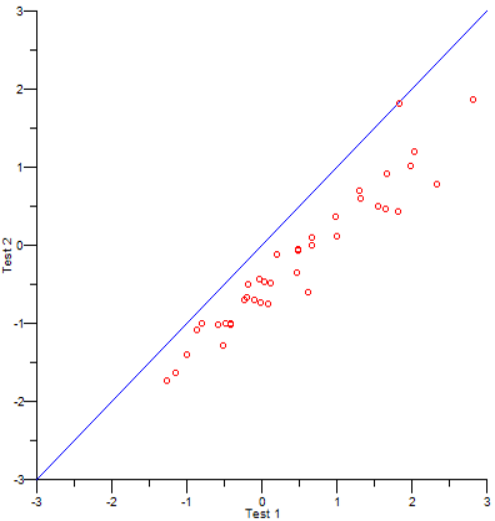



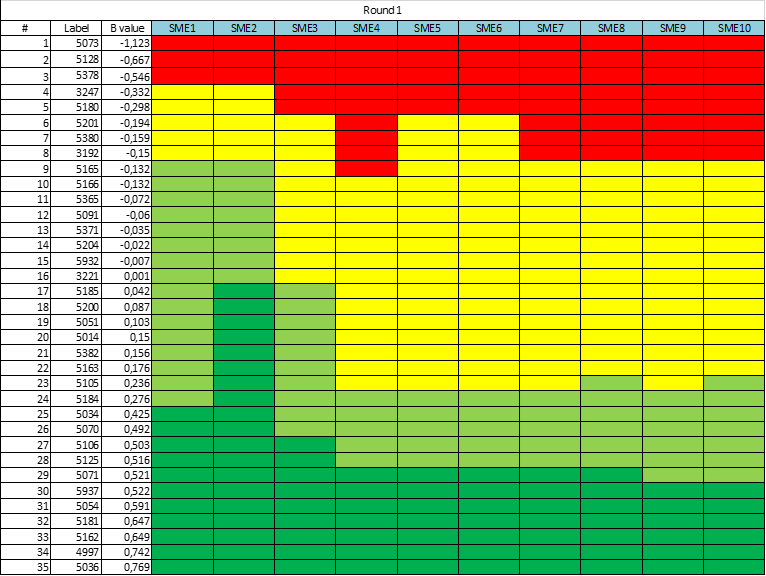
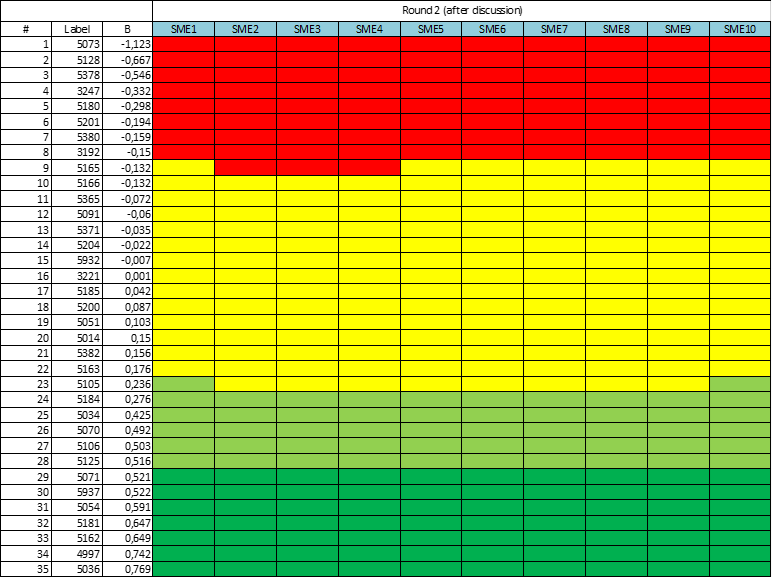




 ASC’s comprehensive platform provides you with all the tools necessary to develop and securely deliver psychometric assessments. It is equipped with powerful psychometric software, online essay marking modules, advanced reporting, tech-enhanced items, and so much more! You also have access to the world’s greatest
ASC’s comprehensive platform provides you with all the tools necessary to develop and securely deliver psychometric assessments. It is equipped with powerful psychometric software, online essay marking modules, advanced reporting, tech-enhanced items, and so much more! You also have access to the world’s greatest